Overprovisioned? How to rightsize without the risk
Being overprovisioned does not always mean wasteful. This guide walks through what it actually means, when to leave it alone, and how to rightsize your cloud without creating new risks.

The word "overprovisioned" gets treated like a diagnosis. More often than not, it is just a number without enough context.
A resource running at 20% Central Processing Unit (CPU) utilization might be worth addressing. Or it might be exactly where it should be. The label alone does not tell you what to do about it, and acting without that context is where rightsizing efforts tend to go sideways.
This guide is built around the distinction between overprovisioning that is intentional and overprovisioning that is quietly compounding. It walks through what overprovisioning means, when it is worth addressing, and how to approach rightsizing in a way that holds up over time.
What does being overprovisioned mean?
Overprovisioning happens when a cloud resource's allocated capacity exceeds what its workload demands, not just once, but as a pattern over time. In practice, that looks like:
- CPU cores running idle most of the day
- Memory headroom that never gets used
- Storage provisioned for growth that has not arrived yet
It is a snapshot, not a fixed state
Think of it like checking the weather at noon and deciding what to wear for the whole week. A resource that looks perfectly sized on a monthly average might be underprovisioned during peak hours and overprovisioned the rest of the time.
This is why two things matter as much as the utilization number itself: how long you look back, and whether you are looking at average behavior or peak behavior.
The observation window changes the picture

How long you look back shapes what you see:
- A 30-day average tells you what a resource looks like under normal conditions
- A 90-day view that accounts for seasonal patterns, anomalies, and traffic spikes tells you what it needs to handle the full range of demand
There is no universal right answer, but the more variable the workload, the longer the lookback window you need.
Average vs. peak utilization
Window length is one part of the picture. The other is which metric you look at within that window.
Average utilization can be misleading in two common scenarios:
- Steady-state workloads at moderate utilization. A resource averaging 60 to 70% CPU in production is not necessarily overprovisioned. That headroom gives autoscaling time to respond by adding capacity horizontally, and absorbs unexpected spikes that fall outside any planned schedule.
- Workloads with irregular peaks. A resource averaging 15% CPU on a normal day but climbing sharply during a product launch or seasonal event tells a similar story. The average does not reflect what the workload needs when demand is highest.
The right approach depends on how predictable the traffic is. Scheduled scaling can handle anticipated peaks without permanent overprovisioning. For spikes that are irregular or hard to forecast, building in headroom is more reliable.
The more useful question is not what a resource uses on a typical day, but what it needs to handle the full range of demand placed on it. That distinction matters every time a rightsizing recommendation is made.
Two types of overprovisioning worth knowing
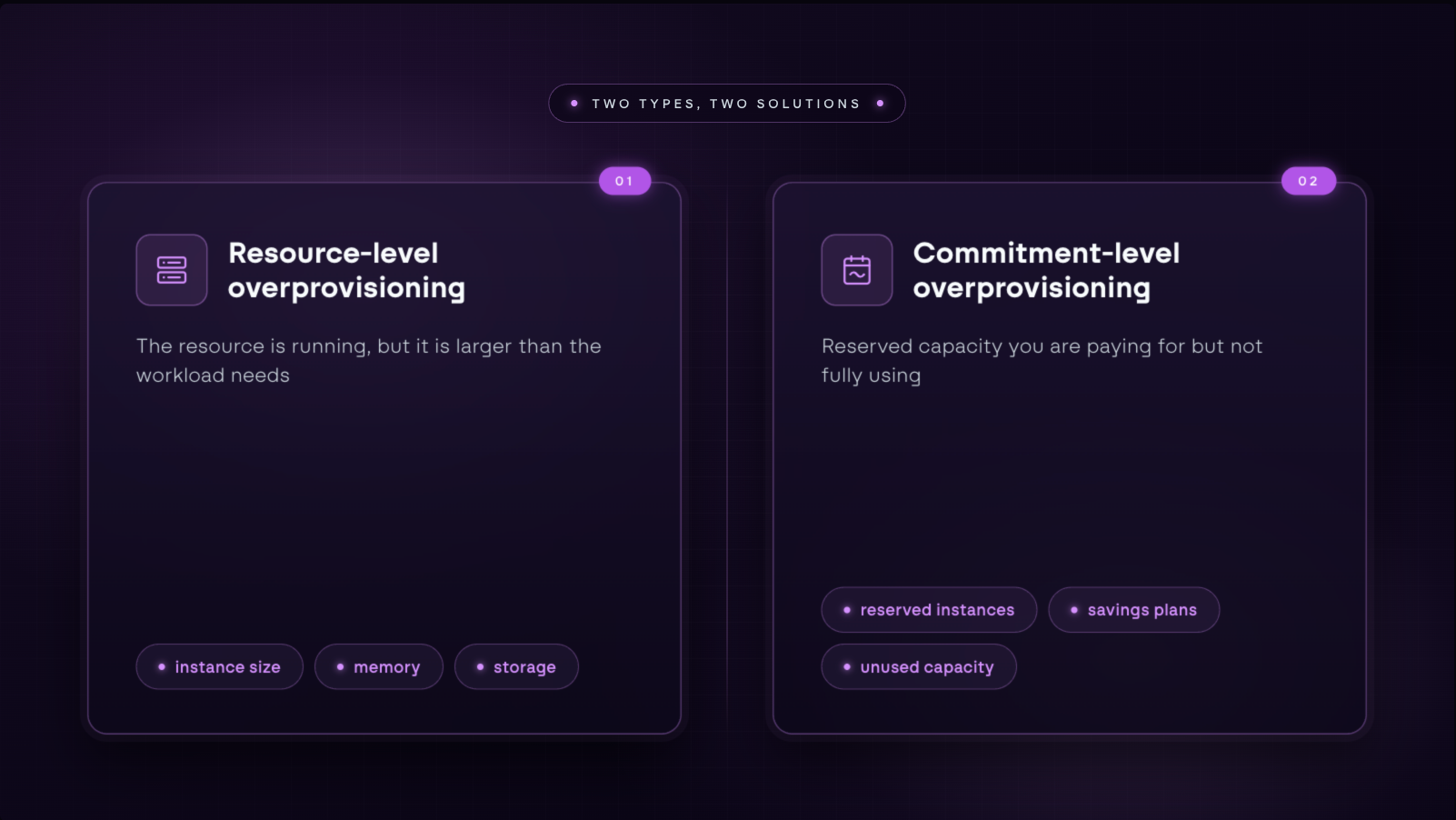
Overprovisioning shows up at two different levels, and they are solved differently:
- Resource-level overprovisioning is about instance size, memory allocation, and storage configuration. The resource exists and is running, but it is larger than the workload needs.
- Commitment-level overprovisioning is about reserved capacity you are paying for but not using. You committed to a certain level of usage, and your usage came in below it.
This guide focuses on resource-level rightsizing. For a deeper look at the commitment side, read our cloud resource management guide on how rate optimization works.
When being overprovisioned is the right decision
Not all overprovisioning signals a problem. Some of it is deliberate engineering judgment, and understanding that distinction is what turns rightsizing into a practice that compounds over time.
Here are the cases where provisioning more than average demand is often the right call.
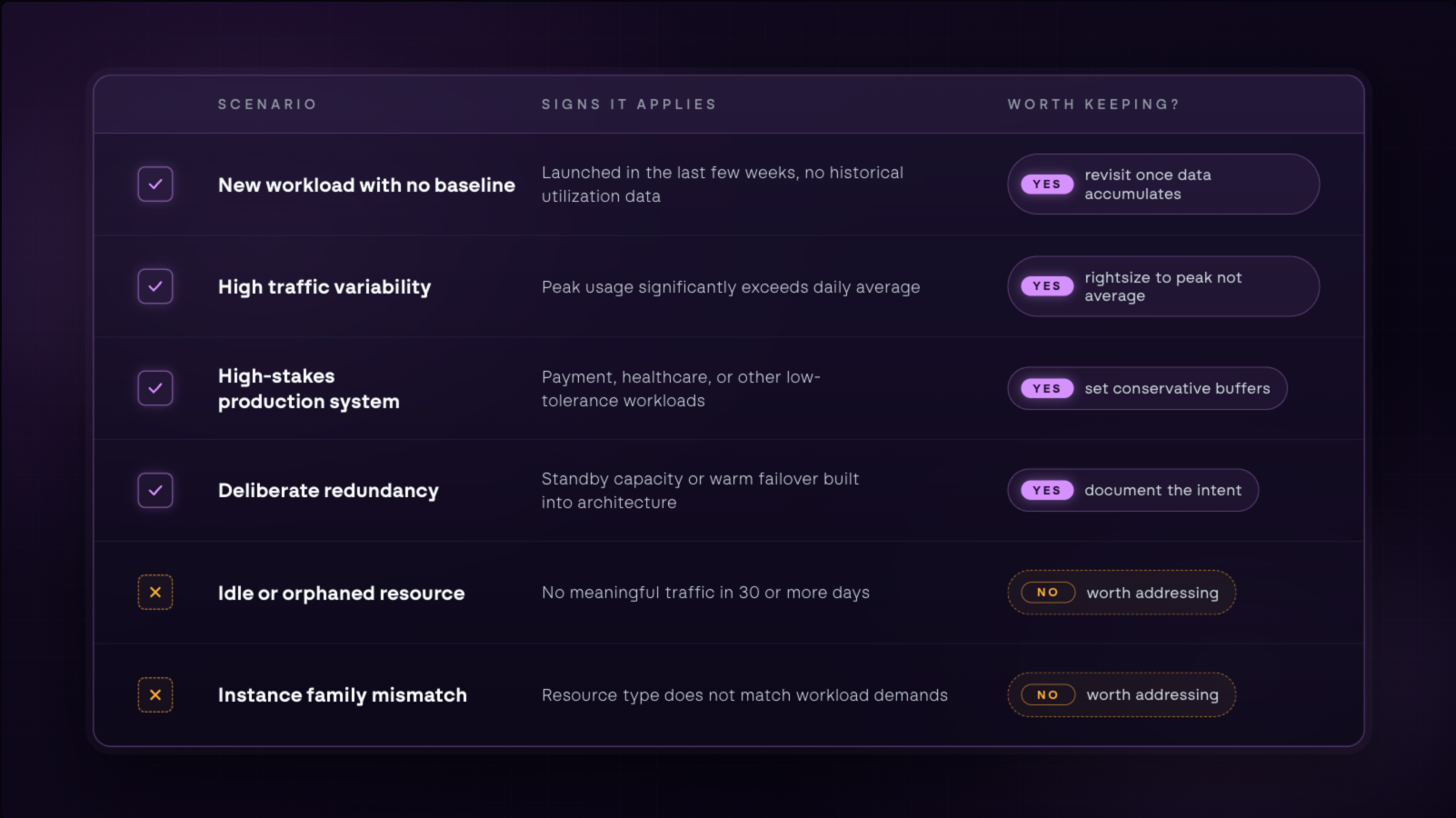
New workloads with no utilization baseline
You cannot rightsize what you have not observed. When launching something new, there is no historical data to draw from, no traffic patterns to analyze, no peak behavior to account for. Provisioning generously at the start and watching what unfolds is the responsible move.
Once a few weeks of data have accumulated, starting with a longer lookback window is a low-risk way to build a reliable baseline before making any changes.
Workloads with meaningful traffic variability
As covered in the previous section, average utilization does not capture the full picture. A service with meaningful variability needs its buffer to accommodate its peak, not its average. Rightsizing to the average leaves that workload exposed exactly when it matters most.
High-stakes production systems
The risk calculus is different in production. A dev environment can tolerate a resource running lean. A payment processor or a healthcare data pipeline cannot. Applying the same rightsizing thresholds across all environments does not simplify the problem, it moves it somewhere more expensive to fix.
Deliberate redundancy built into the architecture
Some overprovisioning is architecture. Standby capacity, warm failover configurations, and buffers designed to absorb failover load are all intentional choices. They exist because the cost of being wrong in the other direction is too high.
Think of it like a hospital keeping backup generators on standby. Nobody calls that waste. The same logic applies to cloud infrastructure where availability is non-negotiable.
Understanding why a resource is provisioned the way it is before making changes is what keeps rightsizing from creating reliability risks.
Putting it together
Rather than asking "are we overprovisioned?", the question worth asking is: "is this overprovisioning intentional, and is the rationale still valid?"
When overprovisioning deserves a closer look
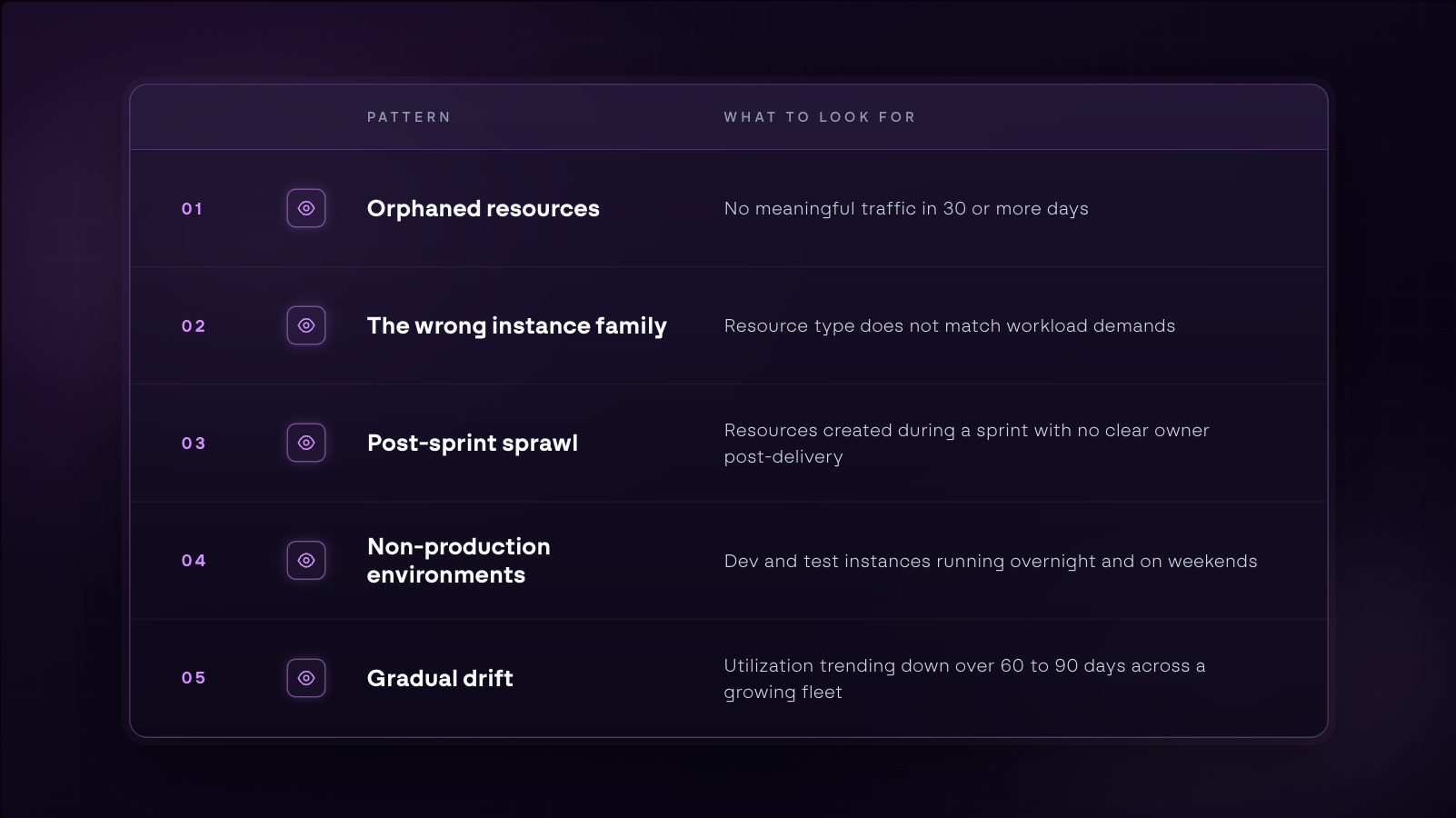
Some patterns tend to surface meaningful savings when examined. Here is what to look for.
Orphaned resources
Orphaned resources are cloud assets that no longer serve an active purpose but continue running and billing. Infrastructure from projects that ended, services that were deprecated, and migrations that completed can all fall into this category.
This tends to persist not because of negligence, but because nobody was quite sure whether something else depended on it. A quick visibility check is usually all it takes to find out, and once confirmed, removing them is the most straightforward rightsizing action available.
The wrong instance family
Cloud providers offer different instance families designed for different types of work. Compute-optimized instances handle CPU-heavy processing, memory-optimized instances handle data-intensive workloads, and general-purpose instances sit somewhere in between.
When a workload and its instance family are mismatched, you end up paying for resources the workload cannot use. A memory-optimized instance running a compute-heavy job has memory sitting idle while the CPU strains. The inefficiency runs in both directions, and it often goes unnoticed because utilization numbers alone do not tell you whether the right kind of capacity is being used.
Think of it like buying a truck to commute to work alone every day. The truck has the capacity to haul cargo, tow trailers, and handle rough terrain, but none of that capability is being used. You are not just paying for more than you need. You are paying for an entirely different set of capabilities than the job requires, and the mileage reflects it.
When this pattern appears, right-typing the instance to a better-matched family often delivers more value than simply downsizing within the same family.
Post-sprint sprawl
Engineering teams spin up resources quickly under deadline pressure, deliver the sprint, and move on, leaving behind infrastructure that was meant to be temporary but has no clear expiration date.
A startup that went through an intensive AI development sprint burned through $50,000 to $60,000 in a single week, not because anyone made a bad decision, but because the infrastructure outlasted the urgency and nobody had visibility into what was still running. By the time the bill arrived, the sprint was long over.
Non-production environments running continuously
Nights and weekends represent more than 65% of the week. If dev and test environments are running through all of it, that is worth a closer look.
These environments exist to support engineering work, and when no engineering work is happening, the case for keeping them running around the clock is worth revisiting.
Gradual drift across a growing fleet
A handful of slightly oversized instances is a rounding error. The same pattern across hundreds of instances adds up to material spend, and it gets there gradually enough that no single moment triggers a review.
From understanding what is overprovisioned to rightsizing It
Knowing when overprovisioning is intentional and when it deserves attention is half the work. The other half is knowing what to do about it.
The sections that follow cover what rightsizing involves, where it tends to get complicated, and how to build an approach that holds up as your infrastructure grows.
What is rightsizing in cloud cost optimization?
Rightsizing is the practice of matching cloud resource specifications to what a workload demands. That means instance type, instance size, storage configuration, and memory allocation should all reflect real usage patterns rather than the estimates made when the resource was first created.
One thing worth clarifying: rightsizing is not a cost-cutting exercise in itself. Downsizing a resource that cannot handle the reduction creates incidents that tend to cost more to resolve than the savings were worth. The goal is to match the resource to the workload, not to make it as small as possible.
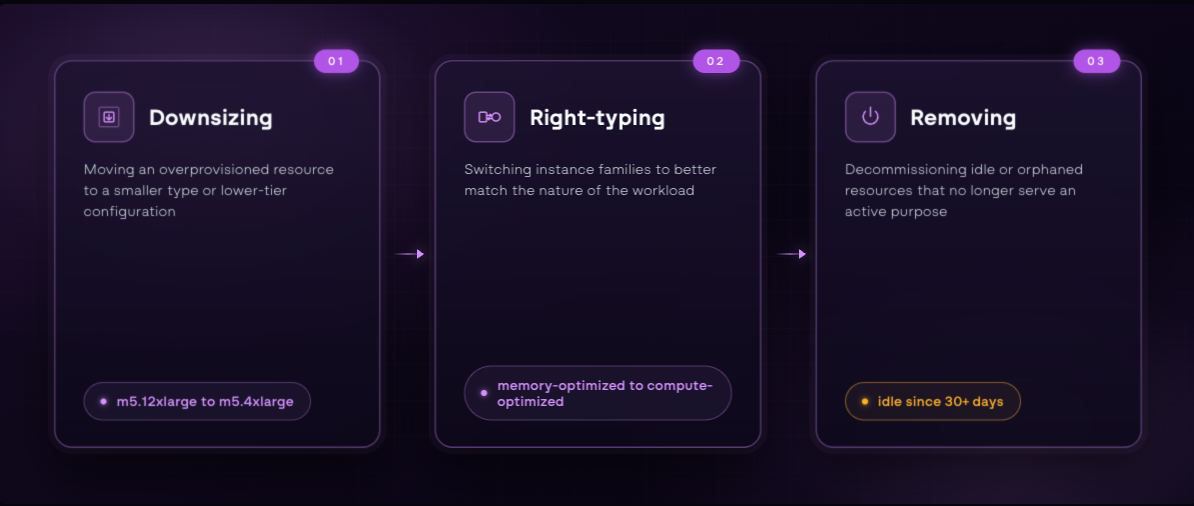
The three forms rightsizing takes in practice
- Downsizing is moving an overprovisioned resource to a smaller type or lower-tier configuration. It is the most common form and the one most conversations focus on.
- Right-typing is switching instance families to better match the nature of the workload. As covered in the previous section, a workload running on the wrong instance family is paying for capabilities it cannot use. Moving to a better-matched family often delivers more value than simply moving to a smaller instance in the same one.
- Removing is decommissioning idle or orphaned resources entirely. As covered earlier, these are the assets that no longer serve an active purpose but continue running and billing. No resizing required, just identifying what is no longer serving a purpose and turning it off. This is typically the highest-impact form and the most straightforward to act on.
Rightsizing works best as a continuous practice rather than a periodic audit. Workloads change, teams reorganize, and traffic patterns shift. What is right-sized today reflects the environment as it exists now, not as it existed six months ago. This is why the recommendations need to keep pace with the environment rather than reflecting a snapshot in time.
Why rightsizing is harder to sustain than it looks
Most engineering teams have run a rightsizing audit at some point. The challenge is rarely awareness. It is the structural dynamics that make rightsizing difficult to act on consistently and even harder to sustain over time.
Recommendations go stale quickly
Cloud environments change constantly. The infrastructure you are running today may look very different from what any report captured last month, which means the longer a recommendation sits unactioned, the less reliable it becomes.
Acting requires context that is often distributed
Knowing a resource is oversized is not enough to act on it. To make a confident decision, you need to know who owns the resource, what workload it is running, what the risk of changing it is, and what it will save. That context rarely lives in one place. It is spread across teams, tools, and institutional knowledge that can be hard to surface quickly.
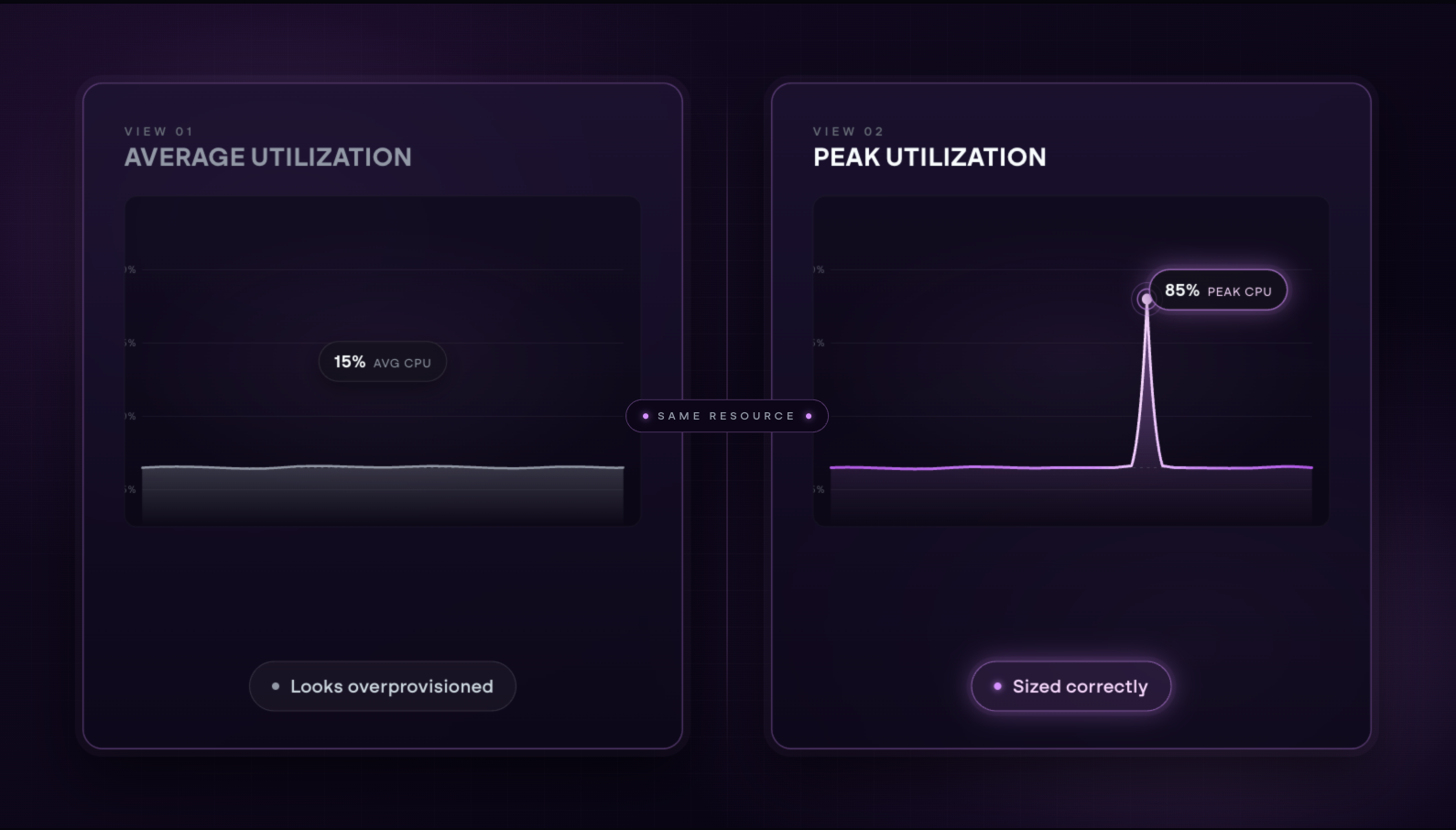
Single-metric analysis misses the full picture
Average CPU utilization is a useful starting point, but it does not capture spike behavior. A resource that averages 15% CPU but regularly spikes to 85% under peak load looks overprovisioned on paper. In practice, it is doing exactly what it needs to do. Recommendations built on averages alone carry more risk than they appear to.
Without a feedback loop it is hard to know what worked
Rightsizing a resource and moving on is only half the practice. Without a way to track whether performance held, whether downstream services were affected, and whether the expected savings materialized, each action is essentially a one-time experiment. The feedback loop is what turns individual actions into institutional knowledge that improves over time.
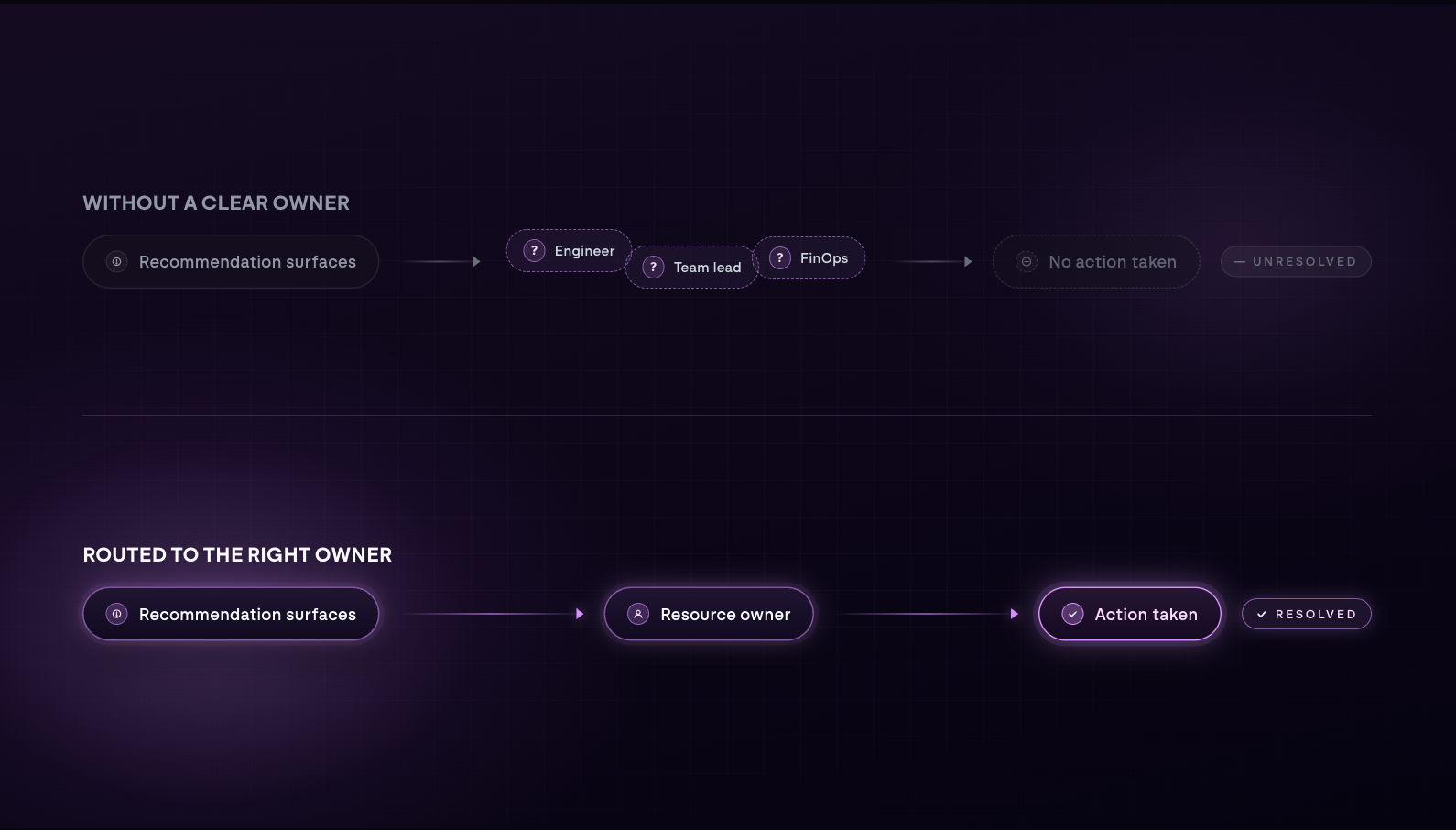
Ownership ambiguity slows everything down
When a recommendation does not have a clear owner, it is easy for it to fall through the cracks. Everyone sees it, but nobody is sure it is theirs to take action. Routing recommendations directly to the team responsible for a resource is what closes that gap.
Six best practices for rightsizing that hold up over time
Before getting into tooling, it helps to have a clear lens for where to focus. Two questions cut through most of the noise:
- Was this provisioning intentional? Did someone make a deliberate choice to provision at this level, or did it happen by default as the environment grew?
- Has it been reviewed recently? Is the reasoning that justified this provisioning still valid, or has the workload, team, or business context shifted since then?
Together, these two questions sort any resource into one of four categories.

The bottom right quadrant is where most recoverable spend tends to live. The best practices below are built around getting there efficiently.
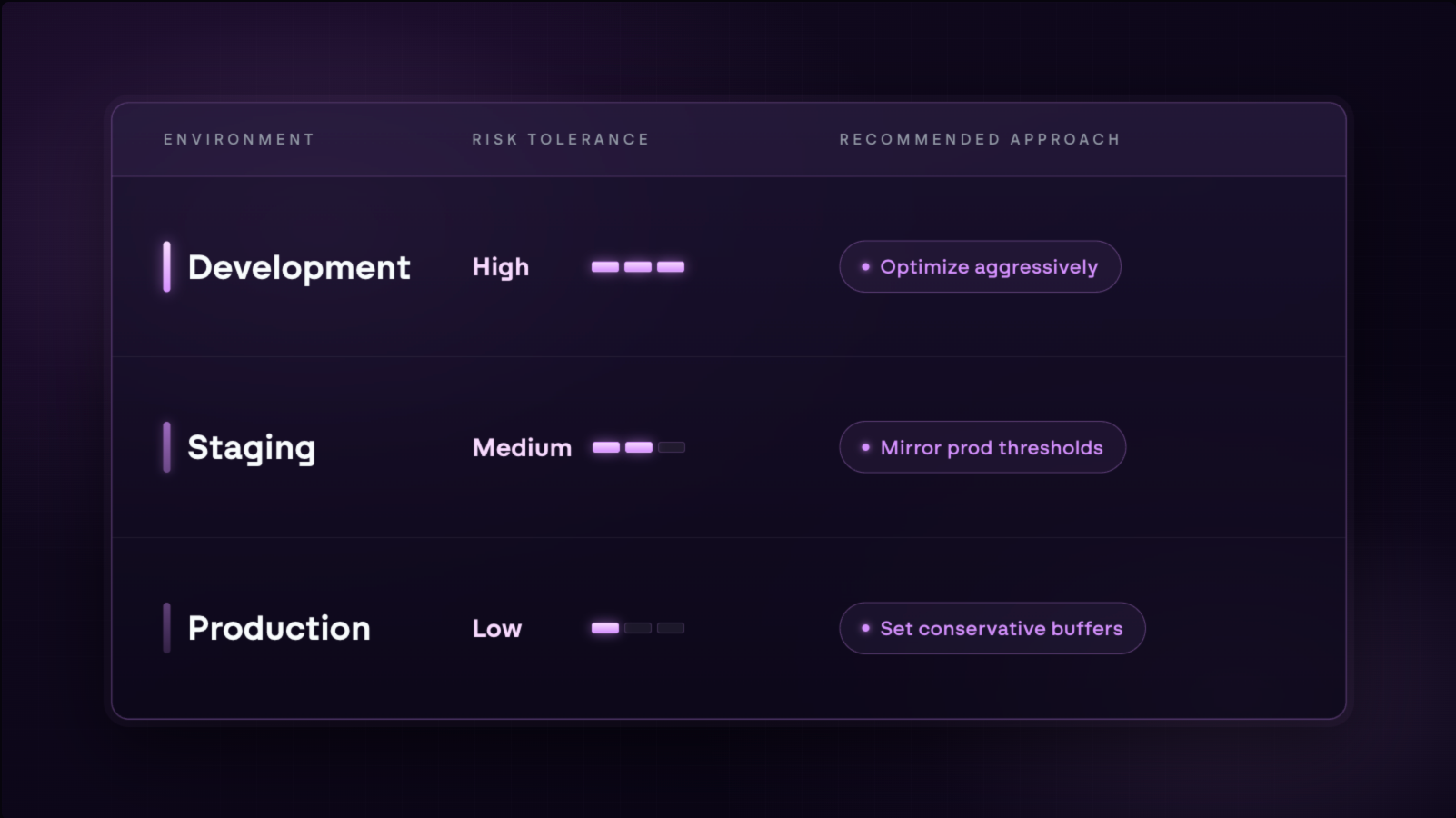
01: Segment by environment first
Production, staging, development, and test environments have different risk tolerances and different definitions of appropriate headroom. As covered in the environment table earlier, what is an acceptable buffer in production is often unnecessary overhead in development.
Establishing the right threshold per environment before applying any utilization criteria keeps rightsizing focused on the right things in the right places.
02: Look at peak behavior, not just averages
Average utilization is a starting point. Building on the observation window section, what a resource needs when demand is highest is what determines whether it is sized correctly.
03: Sort by spend impact, not by number of resources
A long list of slightly oversized small instances can look like a large opportunity. In practice, a handful of significantly oversized large instances often represents more recoverable spend with far less effort. Sorting by spend impact before diving in keeps attention where it is most likely to move the needle.
04: Start with idle and orphaned resources
Among the patterns worth examining, idle and orphaned resources are the most straightforward place to begin. There is no utilization threshold to debate and no performance risk to weigh. If a resource has seen no meaningful traffic in 30 or more days, it is a natural first candidate.
05: Consider instance types before downsizing
Before reducing the size of an instance, ask whether it is in the right instance family for the workload it is running. As the wrong instance family section showed, moving to a better-matched family often delivers more value than moving to a smaller instance in the same one.
06: Build in a review cycle after every change
Every rightsizing action is worth a utilization check two to four weeks later:
- Did the workload perform as expected?
- Did anything downstream shift?
- Did the savings materialize?
This review cycle is what turns individual actions into a reliable practice rather than a one-time cleanup.
Why configurable thresholds matter
The two diagnostic questions at the start of this section only work if your tooling understands the answers.
Configurable thresholds are how you communicate intent to the system. If your production environment is intentionally running at 50% headroom, the tool needs to know that so it stops surfacing it as an opportunity. Without that configuration, intentional buffers and accidental waste look identical, and the recommendations become too noisy to act on reliably.

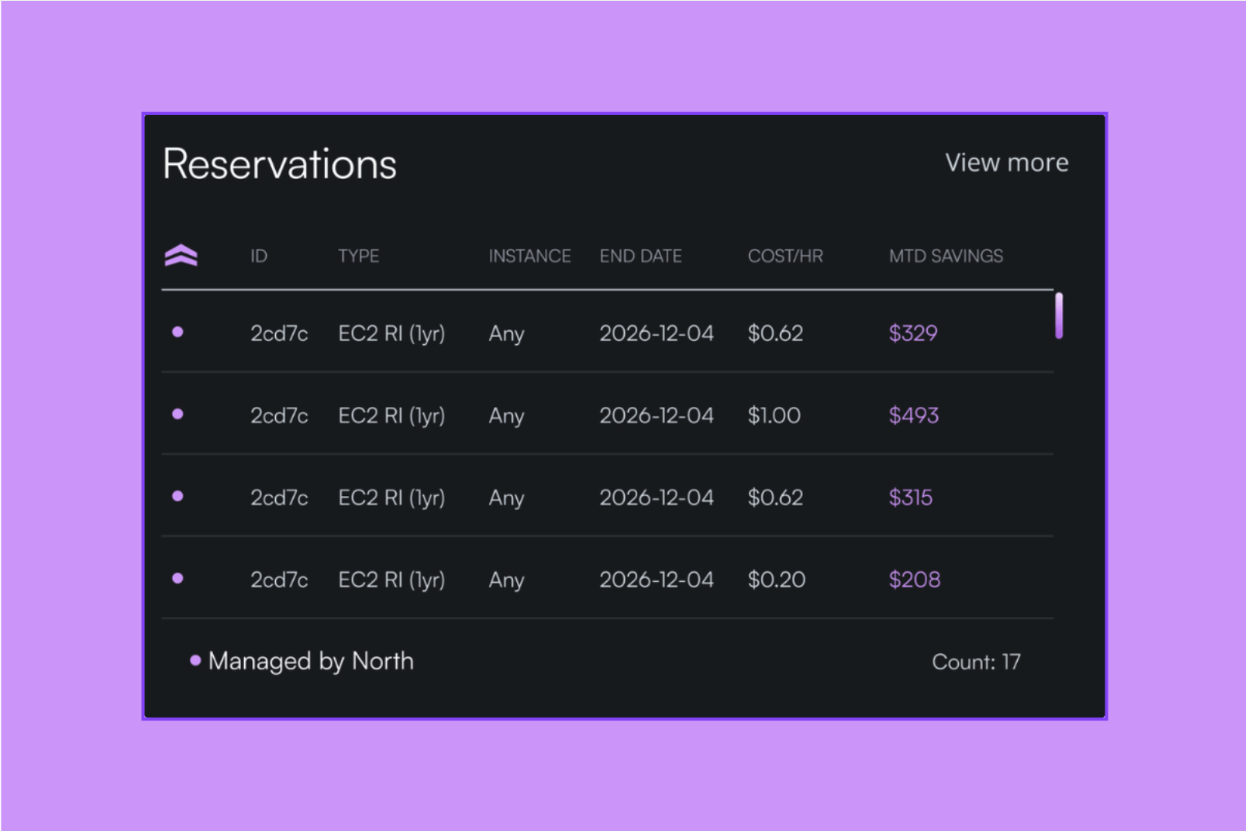
How to approach rightsizing with North
The best practices above describe what good rightsizing looks like. Reshaping, North's continuous infrastructure optimization tool, is how those practices get put into action. It uses advanced machine learning to continuously monitor your cloud infrastructure, adapts to your unique workload patterns, and retrains itself based on the changes you implement and the real-world outcomes of those modifications. Here is what that looks like step by step.
Step 1: Connect your account
North connects to your cloud account in minutes with no infrastructure to deploy and no lengthy onboarding. Within 24 hours, Reshaping has analyzed your environment and surfaced its first set of recommendations, giving your team something concrete to work from on day one.
Step 2: Configure your analysis preferences
Before Reshaping surfaces recommendations, tailor the analysis to your environment:
- Lookback period: choose 14, 32, or 93 days. Longer lookbacks yield deeper insights for variable or seasonal workloads. The default is 32 days.
- CPU and memory headroom: set thresholds per your risk tolerance. Defaults are conservative.
- CPU utilization percentile: choose P90, P95, or P99.5 depending on how much spike behavior you want to account for.
- Scope: configure organization-wide, by specific account, or down to individual resources.
This configuration is how you communicate intent to the system. When Reshaping understands which headroom is deliberate, it stops surfacing intentional buffers as opportunities and focuses on what is worth addressing.
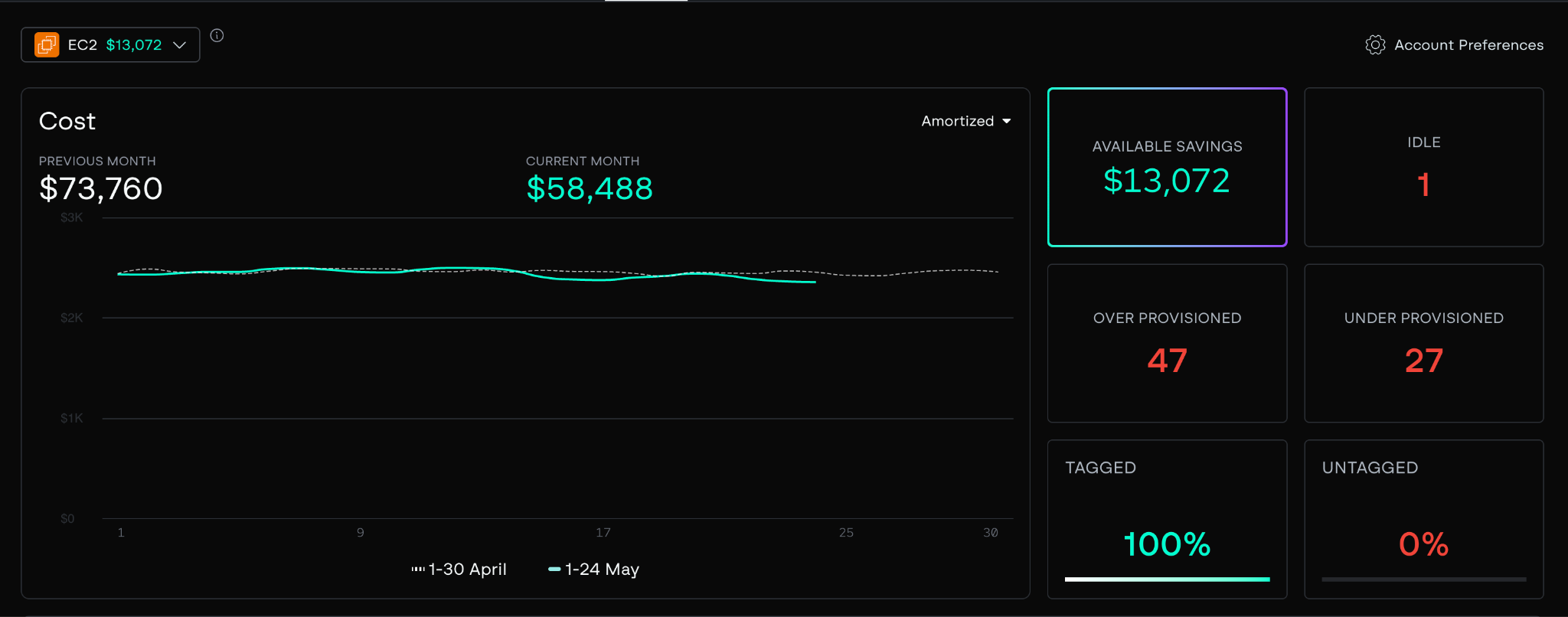
Step 3: Review recommendations by impact
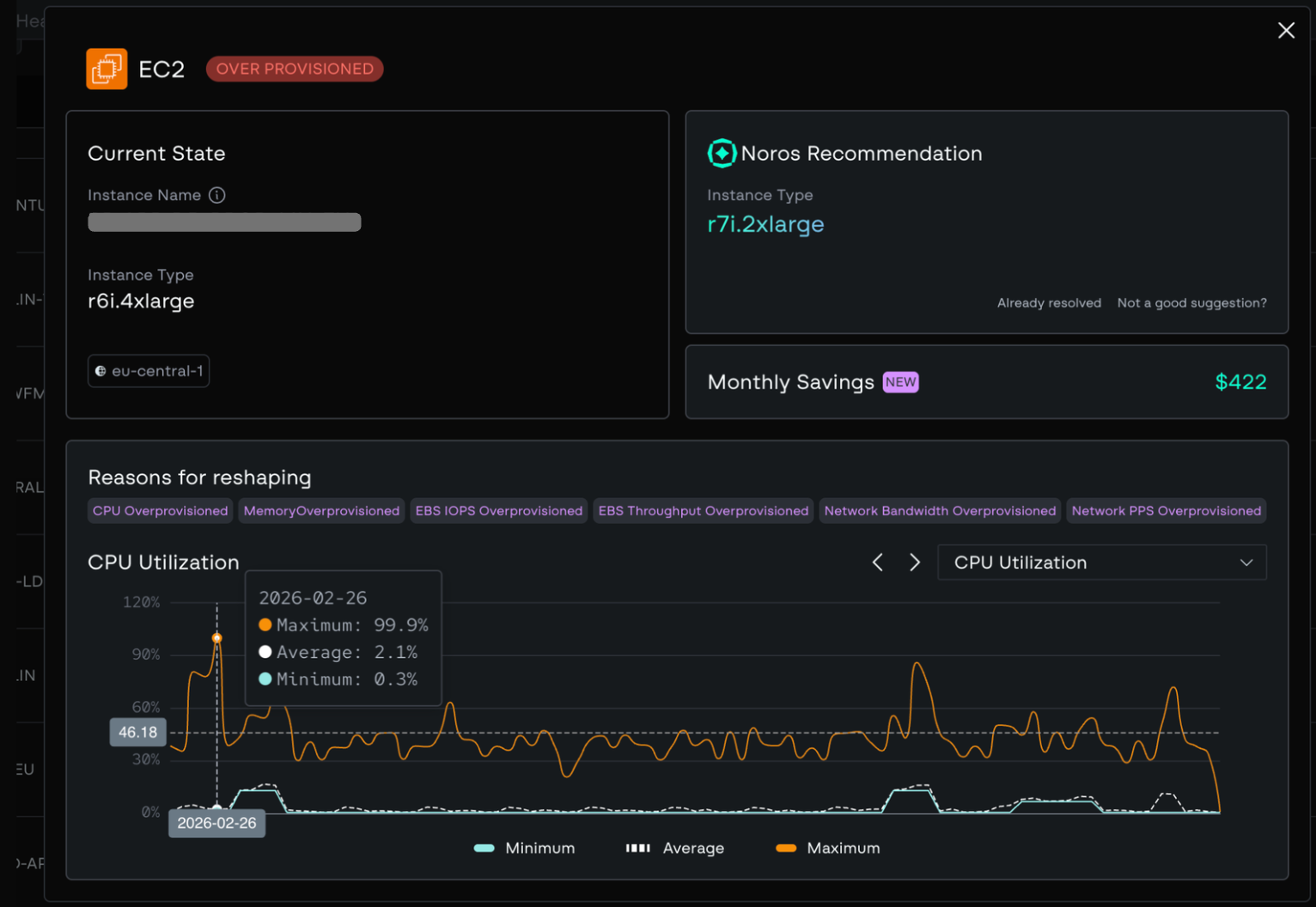
The dashboard displays a curated list of AI-driven suggestions, each rated as over-provisioned, under-provisioned, or optimized. Every recommendation includes:
- Current vs. recommended configuration
- Monthly savings or performance gains
- Migration complexity
- Underlying analytics including utilization history, risk headroom, and anomaly notes
Recommendations can be reviewed, accepted, ignored, or bulk applied directly from the dashboard. Change tracking and effectiveness metrics are stored so you can see the realized impact over time.
Step 4: Check both directions
Reshaping surfaces both recommendations to save money by downsizing where possible and guidance to upsize resources that are performance-constrained. A workload straining against an undersized instance creates its own costs. Rightsizing is about fit, and fit works in both directions.
Step 5: Route to the right owner
Share any recommendation directly with your team via Slack, by creating a Jira ticket, or by sending by email, all from within North's platform. The recommendation reaches the right person with the reasoning, the estimated savings, and the migration complexity already attached, streamlining decision-making and speeding up implementation.
Step 6: Let the system learn
When you apply a suggestion, results are measured and fed back into the ML system. Models retrain continually, growing more accurate as your infrastructure and requirements evolve. All recommendations are stored, versioned, and tracked with account and resource granularity, and historical effectiveness metrics are available for review.
Get started with rightsizing today
Overprovisioned is a description, not a diagnosis. A resource running below its allocated capacity might be wasteful, or it might be exactly where it needs to be. The difference comes down to context, and building a practice around that context is what makes rightsizing sustainable.
The teams that get this right are not the ones who cut the most aggressively. They are the ones who know which overprovisioning is intentional, have a clear lens for spotting what is not, and have a system in place that surfaces the rest continuously.
Ready to see what that looks like in your own environment? Start with the best practices in this guide: segment by environment, look at peak behavior, sort by spend impact, and build in a review cycle. From there, the work compounds quickly.
And when those practices need a system to run on top of, North's Reshaping handles the continuous monitoring, ML-driven recommendations, and ownership routing that make rightsizing a practice rather than a project.
Book a demo to see what your infrastructure looks like with rightsizing handled from day one.

Related article
Book a demo
Get started in as little as 5 minutes with no long-term contracts or lock-ins. Pay month-to-month and stay flexible.

Make your cloud work smarter today
Get started in as little as 5 minutes with no long-term contracts or lock-ins. Pay month-to-month and stay flexible.


