EC2 cost optimization: Why your bill keeps climbing
EC2 cost optimization is the continuous process of making sure your instances are the right size, running only when needed, and priced through the right model. This guide covers the main cost drivers, the strategies that work, and how teams that stay on top of it think differently about the problem.
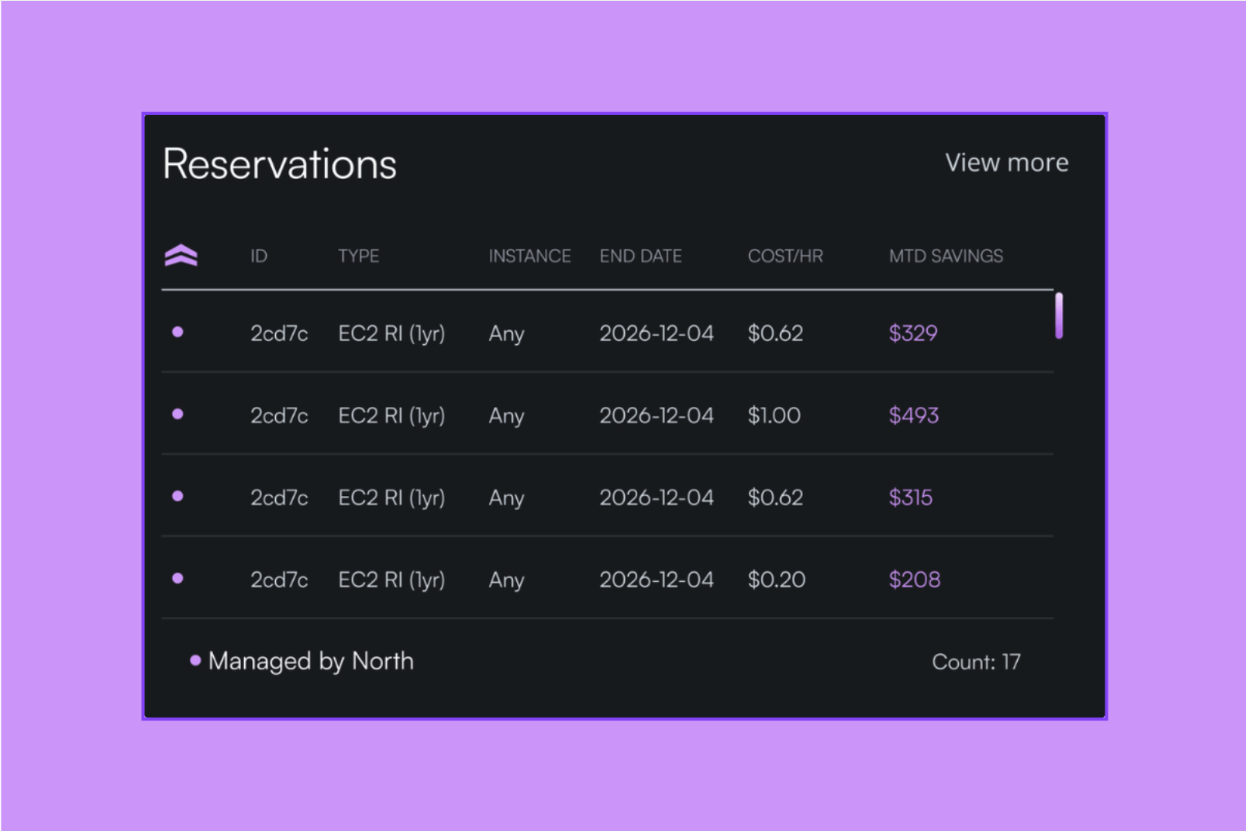
Amazon Elastic Compute Cloud (EC2) cost optimization is the kind of problem that looks straightforward until it isn't. The obvious fixes are well documented: turn off idle instances, rightsize the ones that are too large, buy commitments for workloads that run consistently. Most engineering teams know the list, yet the bill keeps climbing anyway.
The reason is structural. EC2 is not one cost to manage but the foundation almost everything else runs on. Containers, databases, lambdas, managed services: nearly every Amazon Web Services (AWS) workload traces back to EC2 underneath. That is what puts it at the top of most bills, and also what makes it the hardest cost to untangle.
This guide covers what drives EC2 costs at each level, which fixes hold up over time, and how teams that manage it well think about the problem.
Why EC2 is the hardest cloud cost to get right
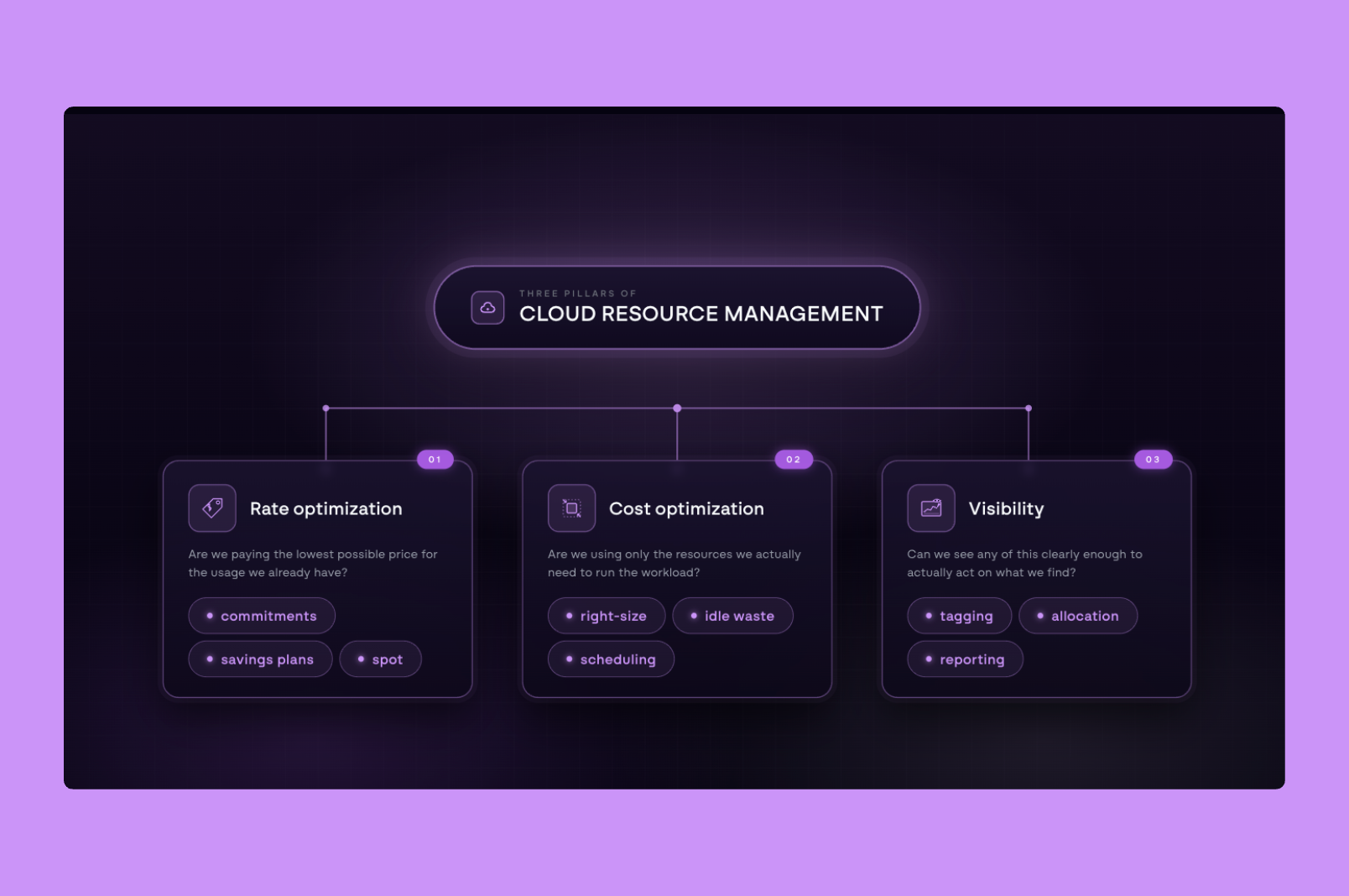
EC2 cost optimization is the continuous process of making sure instances are running only when needed, sized to match actual workload demand, and priced through the most cost-effective model available. The difficulty is that these variables are interconnected, and the problem becomes clearer when broken down into three diagnostic questions that escalate in complexity.
Are you using the machine at all?
The most basic question is also the most commonly skipped. Before asking whether an instance is the right size or priced correctly, it is worth confirming whether it needs to be running at all.
Forgotten test environments, instances spun up for a sprint and never shut down, infrastructure that outlasted the urgency that created it: these are the most straightforward sources of EC2 waste, and they persist because nobody had clear visibility into what was still running.
Are you using the right size?
Once it is clear that an instance is genuinely in use, the next question is whether it is sized correctly for the workload it is running. This is what most EC2 optimization discussions focus on, and for good reason. An instance provisioned generously at launch tends to stay that size long after usage patterns have stabilized.
Cloud instances work a lot like office space in this regard.
- A team of three paying rent on a floor built for twenty is consuming resources that have no corresponding value.
- A team of twenty in a space built for five runs into capacity issues that affect performance.
The right size is specific to the workload, and it changes as the workload evolves.
Are you paying the right rate?
Even a correctly-sized instance that runs only when needed can be significantly overpriced if the payment model has not been thought through.
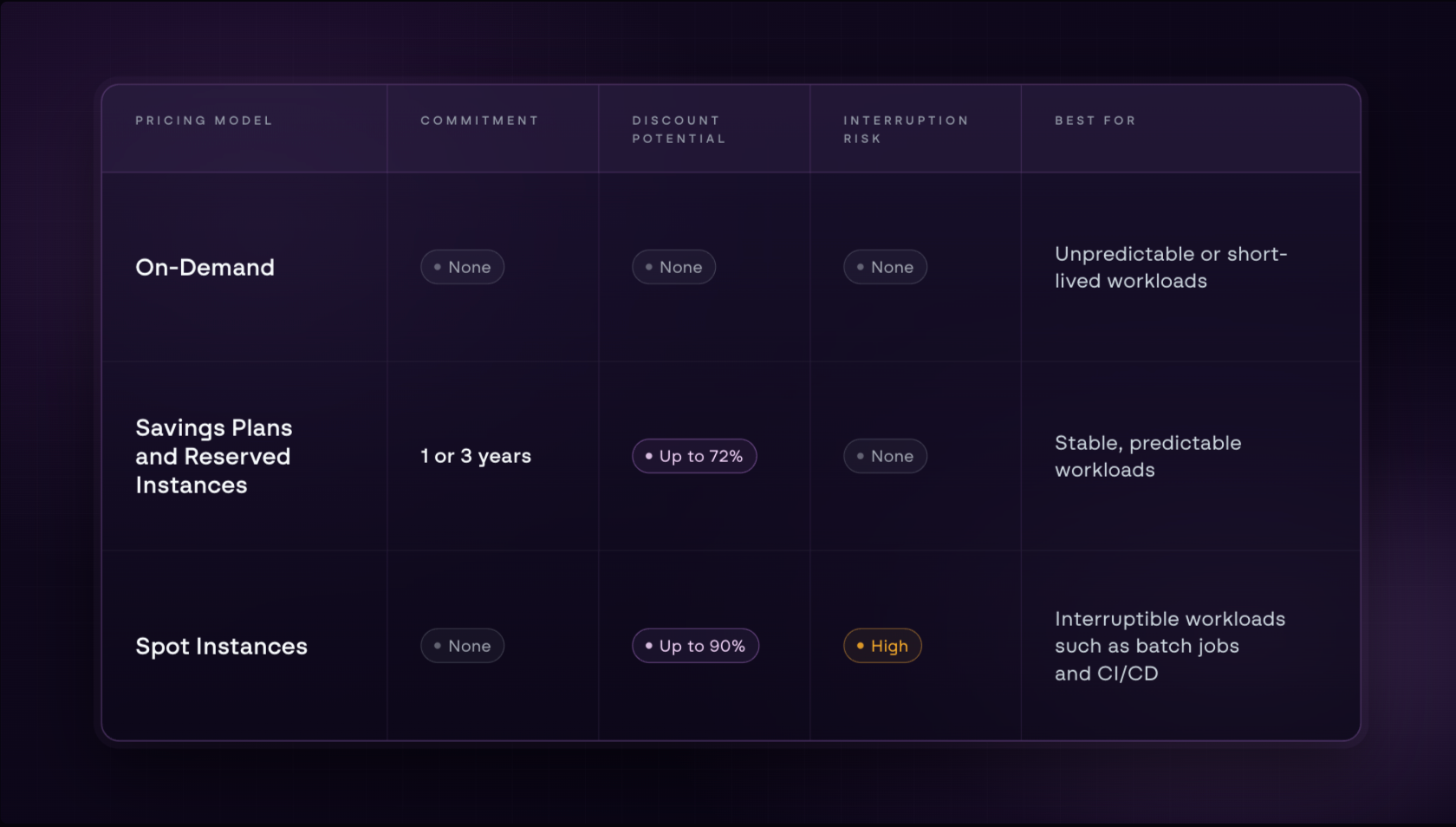
AWS offers three ways to pay for EC2, and the difference between them is substantial:
- On-Demand charges full price with no commitment
- Savings Plans (SP) and Reserved Instances (RI) offer up to 72% off in exchange for a one or three-year commitment
- Spot Instances offer spare AWS capacity at up to 90% off but can be reclaimed by AWS at any time
Each model suits a different type of workload, and choosing the wrong one for a stable, long-running workload is one of the most common sources of avoidable EC2 spend.
Why the order matters
Each of these three questions builds on the one before it, and the sequence matters as much as the questions themselves.
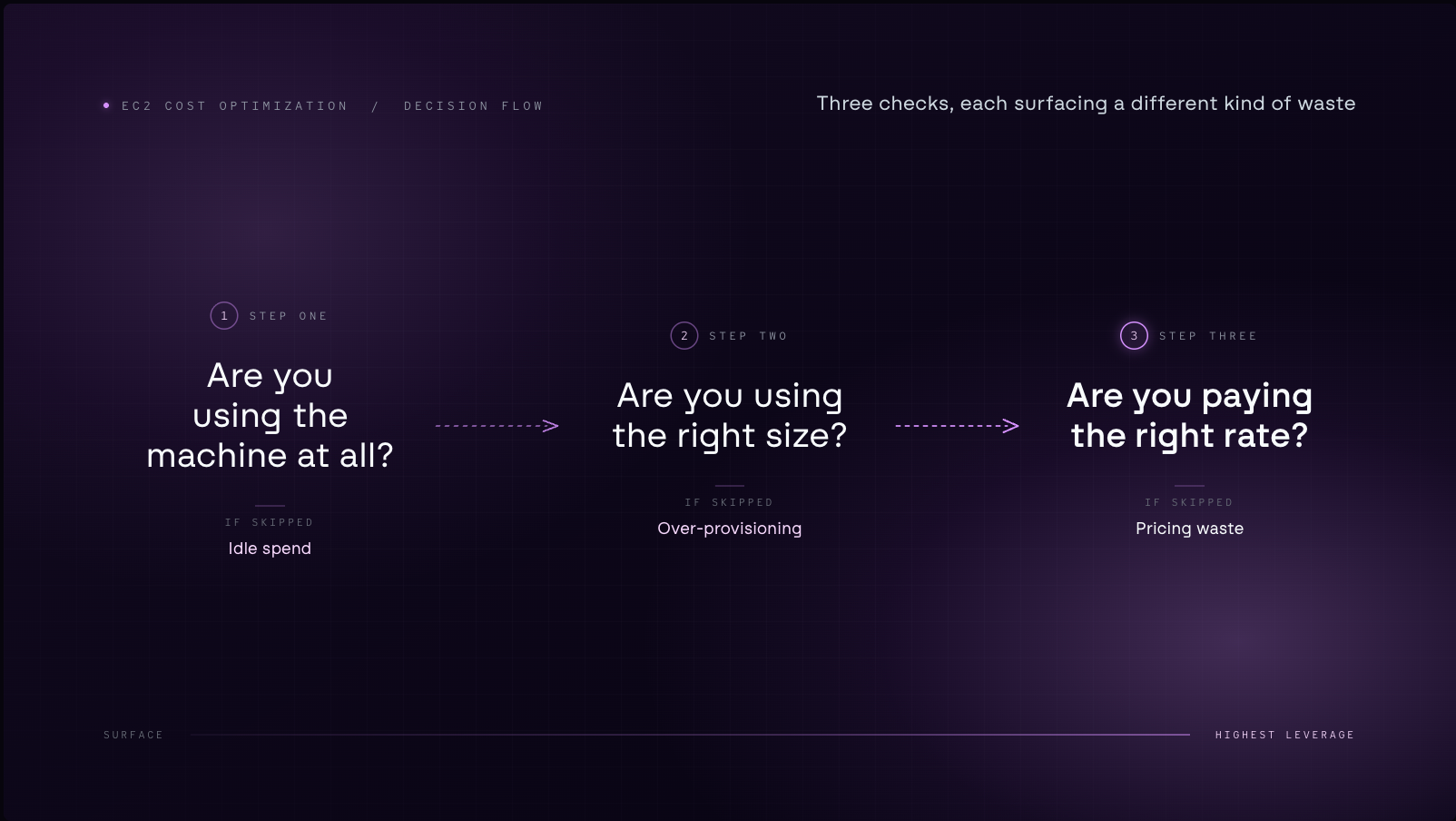
Rightsizing an instance before confirming it is needed wastes the effort. Committing to a pricing model before rightsizing locks in a discount on the wrong baseline. Working through all three in order is what produces savings that hold as the infrastructure evolves.
The commitment layer: EC2's biggest savings opportunity
The pricing model decision is where the most money is either saved or lost, and where teams have the least structured approach. The challenge is not that the options are unclear. Rather that choosing between them requires predicting the future, and most cloud environments change faster than a multi-year commitment can account for.
The challenge with long-term commitments
Committing to EC2 capacity is a lot like signing a multi-year office lease before knowing how many people will actually be in the building. If the team grows, the space fills up and the commitment pays off. If the team shrinks mid-lease, the organization keeps paying for empty desks. Unlike an office lease, unused reserved EC2 capacity cannot be subleased or transferred.
Growth plans change, teams restructure, products pivot, and workloads shift in ways that are difficult to anticipate twelve months out, let alone thirty-six. The math on committed pricing is compelling, and the risk of committing to the wrong baseline is real.
Where commitment strategy tends to get complicated
Most teams navigate this decision thoughtfully but find themselves in one of two situations:
- Staying on On-Demand pricing for workloads that have been running stably for months or years, because the lock-in feels difficult to justify given how much the environment might change
- Purchasing SPs or RIs at the current infrastructure baseline before rightsizing, which secures a discounted rate but on capacity that may be larger than the workload actually needs
Both situations are understandable given the information available at the time. The challenge is that the cost of waiting on commitments, or committing at the wrong baseline, compounds quietly over time.
Instance sizing: The right fit, not the smallest size
Rightsizing means matching an instance type and size to the workload it is running. The goal is not the smallest possible instance but the appropriate one, and that distinction matters more than it might seem. Downsizing a resource that cannot handle the reduction creates performance issues and reliability risks that tend to cost more to resolve than the savings were worth.
How to tell if an instance is oversized
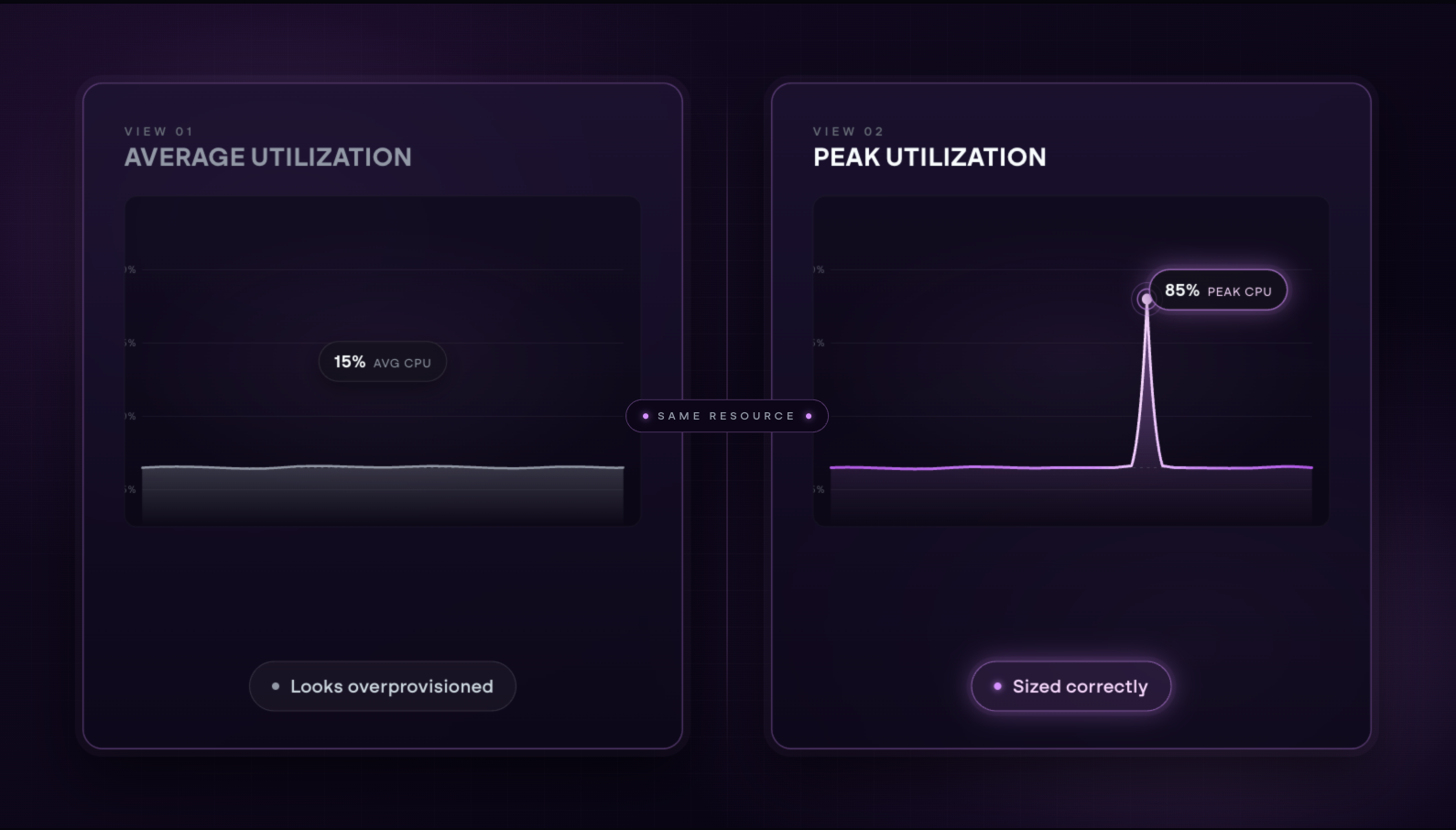
The signal is in the usage data. CPU utilization, memory pressure, and network throughput over a meaningful observation window tell a clearer story than any single snapshot. A machine running at 8% CPU for weeks with no spikes is a reasonable candidate for downsizing. An instance hitting 90% regularly is undersized and poses a reliability risk, even if it has not caused an incident yet.

The length of the observation window matters as much as the metrics themselves. A 30-day average tells you what a resource looks like under normal conditions. A 90-day view that accounts for seasonal patterns, traffic spikes, and anomalies tells you what it needs to handle the full range of demand. The more variable the workload, the longer the window needed to make a confident sizing decision.
The headroom principle
In production environments, some overprovisioning is deliberate and appropriate. Leaving room for unexpected load spikes is sound engineering judgment, and the right utilization target for a production database is very different from the right target for a development environment one engineer uses a few times a day.
The issue is not overprovisioning at launch, before there is usage data to draw from. Instead, it is when that initial decision never gets revisited.
An instance sized generously for a new service in Q1 tends to stay that size through Q4, long after the workload has stabilized and a smaller configuration would serve it just as well. Overprovisioning that was once intentional becomes quiet waste when the rationale is no longer valid but the configuration remains unchanged.
For a deeper look at how to distinguish intentional over-provisioning from the kind worth addressing, this guide on overprovisioning and rightsizing covers that in depth.
Choosing the right instance family
Sizing decisions are not only about going up or down within the same instance type. Choosing the right instance family for the workload is equally important, and a mismatch here tends to go unnoticed because utilization numbers alone do not tell you whether the right kind of capacity is being used.
A memory-optimized instance running a compute-heavy job has memory sitting idle while the CPU strains, and a compute-optimized instance running a memory-intensive database workload creates the same problem in reverse. Moving to a better-matched family often delivers more value than simply downsizing within the same one.

Graviton-based instances are worth particular attention for teams evaluating their instance families. For compatible workloads, the price-performance improvement is meaningful and does not require architectural changes to capture.
The cost nobody expects: Data transfer
Most EC2 optimization conversations focus entirely on compute: which instances are running, how large they are, and what pricing model covers them. Data transfer sits outside that frame almost entirely, which is why it tends to show up as a surprise rather than a line item anyone planned for.
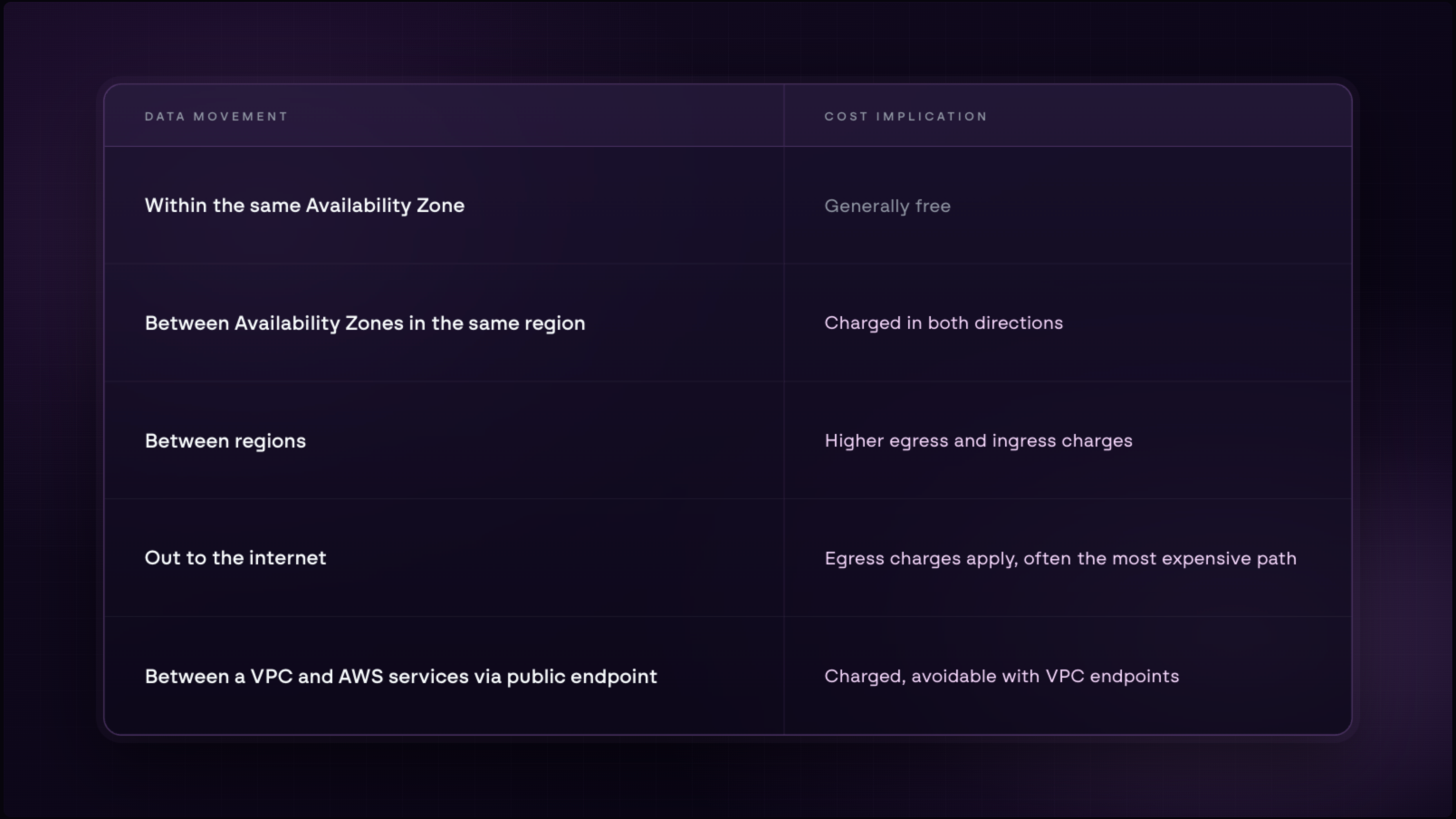
Every time data moves between services, between regions, or out to the internet, AWS charges for it, and those charges accumulate constantly in the background, independent of whether the compute costs look healthy.
Why data transfer is easy to miss
Compute costs are visible, attributable, and tied to decisions engineers remember making. Transfer costs accumulate from architectural patterns that were set up once and never reconsidered, and they do not announce themselves until someone looks at the right part of the bill.
AWS charges for data the moment it crosses a boundary: between regions, between Virtual Private Clouds (VPCs), or out to the internet.
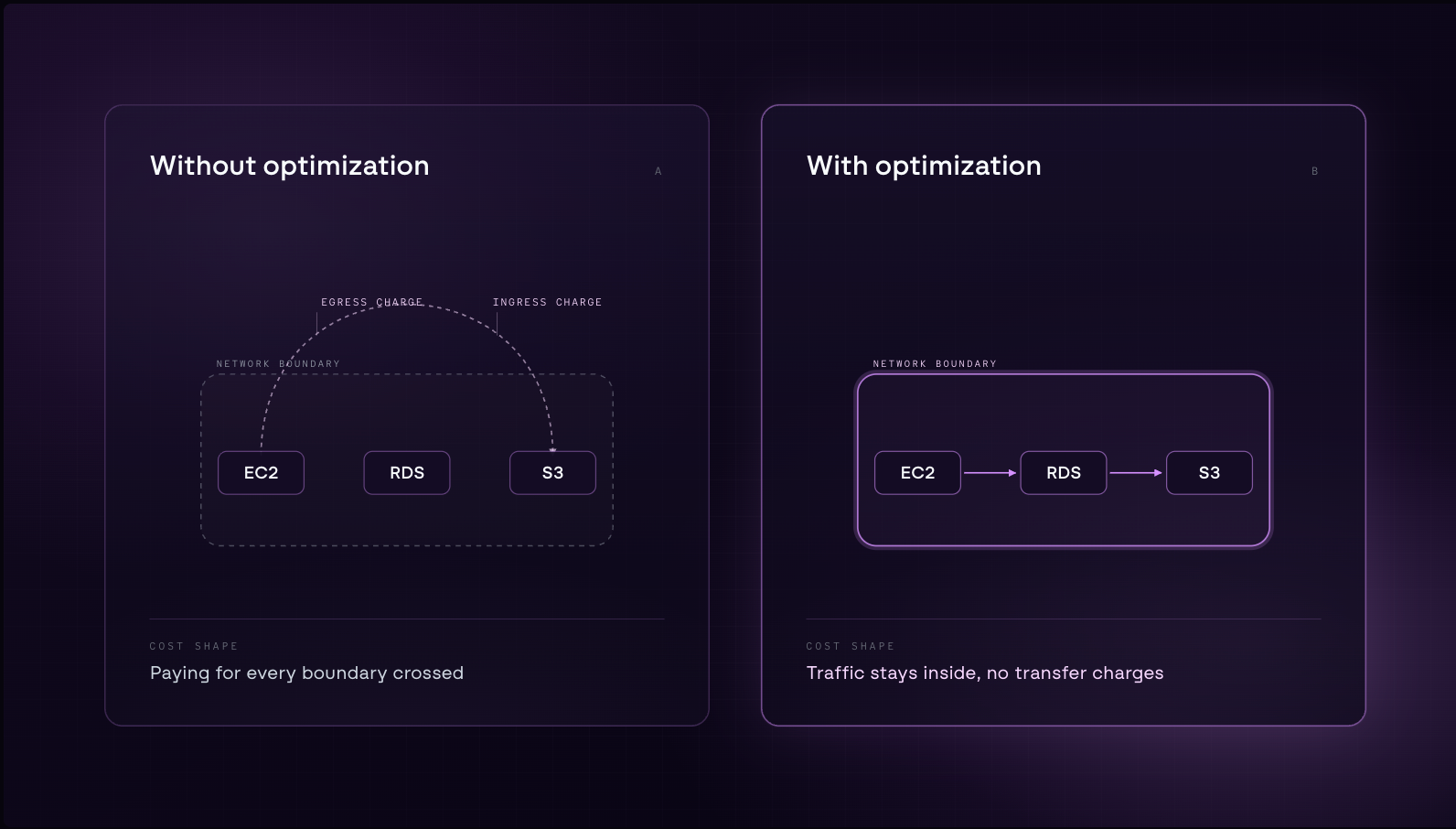
A useful way to picture this is toll pricing on a commute. Traffic that stays within the city moves freely, but the moment it crosses into another zone, there is a charge in each direction. The problem is not just the cost of crossing, rather that many of them are avoidable. Services that could communicate directly are instead taking the long route, paying at every boundary along the way.
Why this matters for EC2 specifically
EC2 instances are often the hub through which other services route. Relational Database Service (RDS) databases, Simple Storage Service (S3) buckets, Lambda functions: when these services communicate with each other through inefficient paths, the transfer costs generated can rival the compute costs themselves. For teams that do not yet have a clear picture of their full AWS bill, data transfer is consistently where the largest surprises live.
What to do about it
Reducing data transfer costs is primarily a code and architecture decision rather than a configuration one. Services that communicate frequently should live in the same network, and the further data travels to get from one service to another, the more it costs.
Practically, this means:
- Keeping services that talk to each other in the same Availability Zone where possible
- Using VPC endpoints to route traffic to AWS services privately rather than over the public internet
- Reviewing service communication patterns to identify routing that crosses regions unnecessarily
- Consolidating workloads that generate high inter-service traffic into the same network boundary
Best practices for reducing EC2 costs
Cost visibility is built into how high-performing engineering teams operate, rather than treated as a project that runs parallel to the actual work. The practices below reflect that orientation: they are habits, not a one-time exercise.
Start with inventory and separate signal from noise
Before optimizing anything, it helps to understand what is actually running, not at the account level, but at the resource level. Which machines are active, what services depend on them, and what purpose each one serves.
A $10,000 monthly EC2 cost that is fully explained and attributable to a specific function is a very different problem from a $10,000 cost where nobody can account for half of it. Once there is a clear picture of what is running, some costs will map cleanly to a business function and be proportional to the workload they support.
The costs worth investigating are the ones that do not map to anything clear, or that seem disproportionate to the workload they support. Optimization without that inventory is guesswork, and it tends to produce savings in the wrong places.
Match scheduling to actual usage patterns
Development and test environments do not need to run around the clock. Nights and weekends account for roughly 65% of the week, and for environments that are only used during business hours, most of that runtime has no corresponding value.
Scheduling instances to run only when they are needed is one of the most straightforward ways to reduce EC2 costs without any change to the underlying infrastructure or workload configuration.
Treat rightsizing as a continuous process
EC2 usage changes constantly. A workload that was correctly sized six months ago may look very different today, and optimization decisions made against stale data carry more risk than they appear to.
Analyzing historical usage patterns on an ongoing basis, rather than as a quarterly exercise, is what keeps rightsizing recommendations reliable.
The most useful signals to track continuously are:
- CPU utilization trends over time
- Memory pressure during peak periods
- Whether instance behavior has shifted since the last time a sizing decision was made
Commit to the right baseline, not the current one
As covered in the commitment section, the sequencing of rightsizing and commitment decisions matters significantly.
The right order is to understand the workload, rightsize against real usage data, and then commit to the validated baseline. Where possible, pooling commitments across multiple teams or accounts rather than purchasing them in isolation gives organizations more flexibility to adjust coverage as individual workloads shift.
Build cost ownership into the team structure

EC2 costs are difficult to manage when they belong to everyone in general and nobody in particular. The teams that stay on top of it treat cost visibility the way they treat performance monitoring: as something visible to the people making infrastructure decisions on a continuous basis, not something reported to finance at the end of the month.
When the engineers who own a service can see what it costs, the feedback loop that drives good infrastructure decisions closes naturally.
How to reduce EC2 costs with North: A step-by-step walkthrough
The AWS bill arrives and EC2 is the loudest line item, again. The number is higher than last month and nobody on the team made a single decision that explains it.
Rather than opening Cost Explorer and working backwards through weeks of usage data, here is what that same investigation looks like inside North, which functions as the control tower for everything that follows.
Step 1: The rate savings surface immediately
Within the first few minutes of connecting the AWS account, Arctic scans historical usage and identifies a pattern that is common but expensive: a significant portion of EC2 spend is being billed at On-Demand rates for instances that have been running continuously for months. These are workloads stable enough to commit to, but nobody pulled the trigger because the lock-in felt risky.
Arctic applies the right SPs and RIs automatically, without requiring a multi-year bet. For most teams, this step alone brings EC2 spend down by up to 51%.
Step 2: The environment comes into focus
Twenty-four hours later, Reshaping has analyzed every EC2 instance in the account. The dashboard shows a clear picture: 66 instances are overprovisioned, 26 are underprovisioned, and one instance has been sitting idle for weeks without anyone noticing.
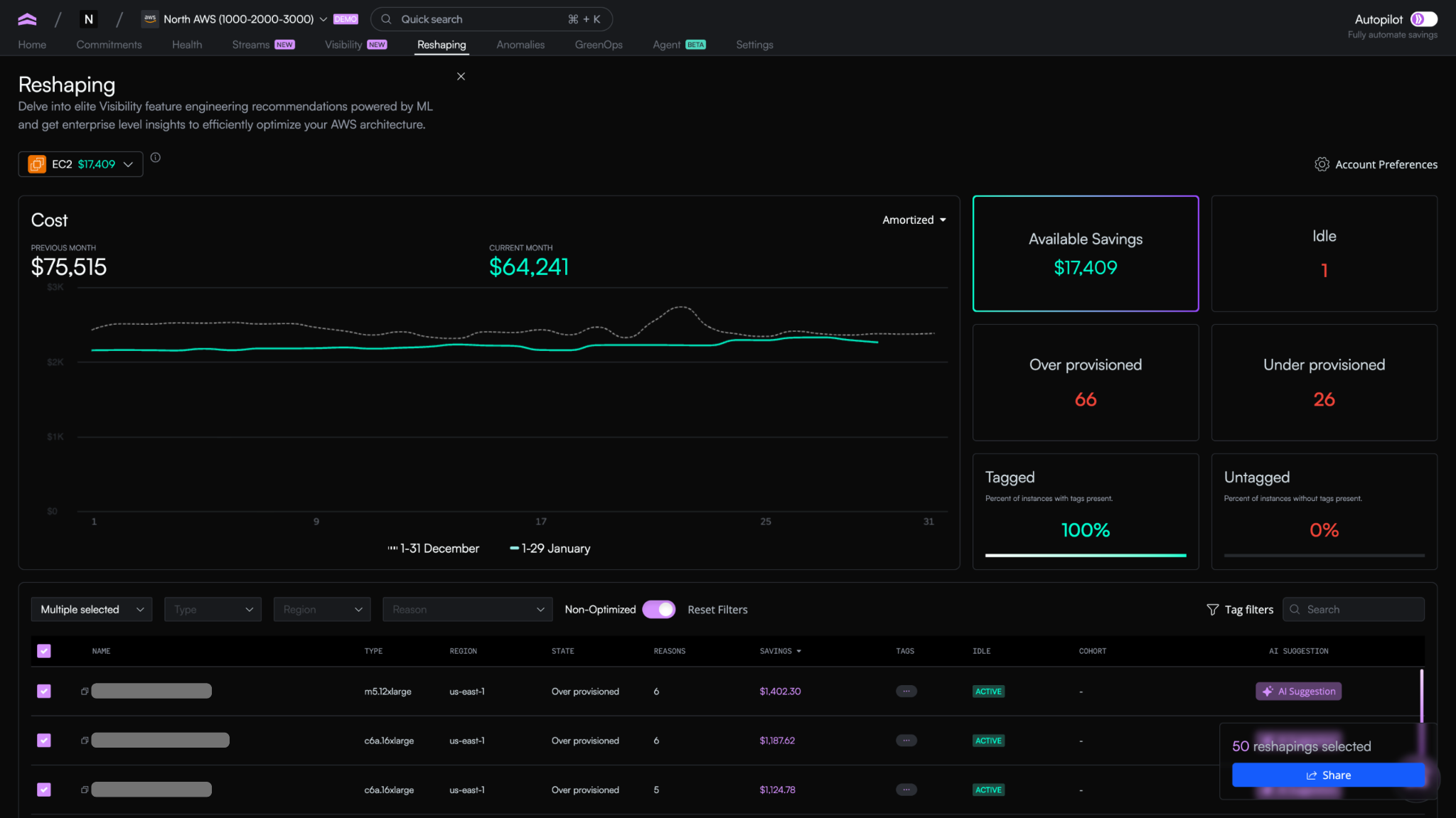
The highest-impact recommendation is an instance running at consistently low CPU utilization. Reshaping flags it, explains why, and quantifies the savings. From the dashboard, you review it and choose to send it to the team that owns it via Jira, Slack, or email, with all the context already attached.
Step 3: A spike appears before it becomes a surprise
A few days later, something shifts. EC2 spend starts climbing in a way that does not match any planned work. North's Anomaly Detection catches it the same day, flagging an unexpected increase at the resource level with a timestamp, a severity rating, and the specific instance driving the change.
It turns out a workload scaled up during a traffic spike and never scaled back down. The team is notified immediately with enough context to understand what happened and resolve it. Without that visibility, the same spike would have shown up as an unexplained line item at the end of the month, weeks after it started accumulating.
Step 4: The CFO asks a question
Later that week, a message arrives from finance. EC2 costs are pacing higher than last month and they want to understand why. Instead of scheduling a meeting or pulling a manual report, the engineer opens Noros and types the question directly: "Why is EC2 spend up this month?"
The response comes back in seconds.
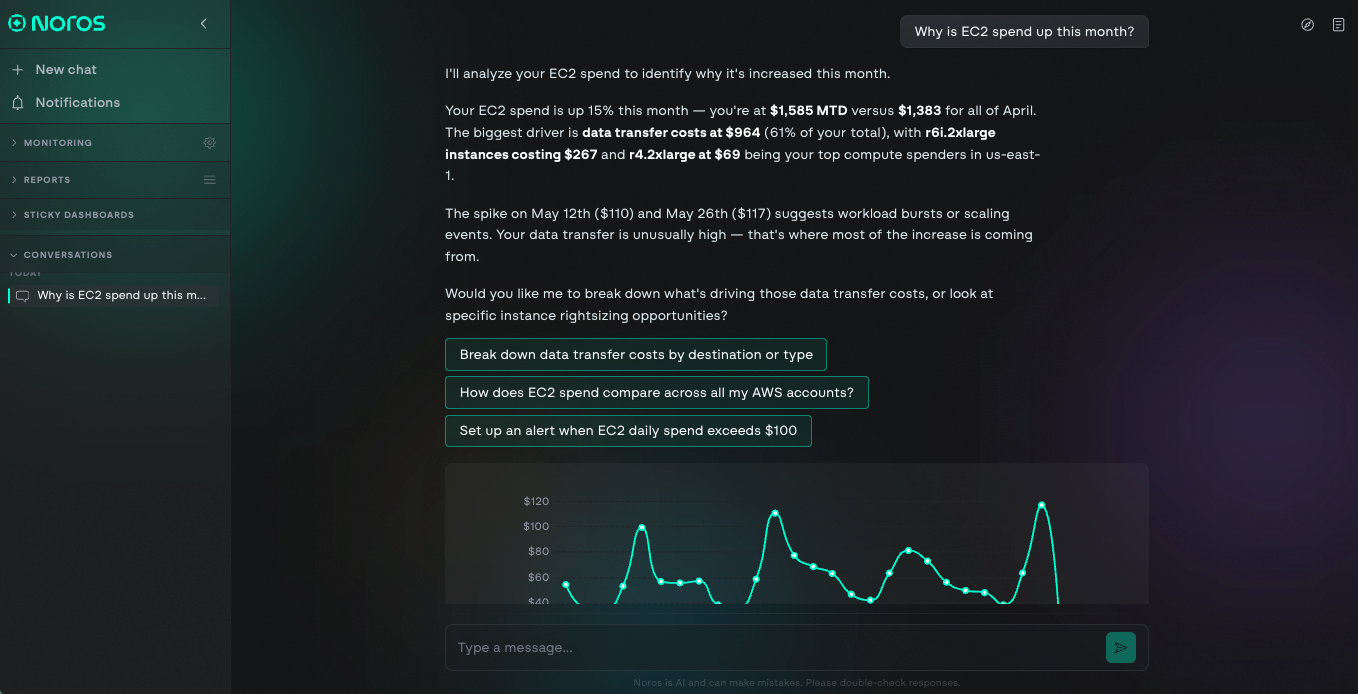
Noros identifies:
- Specific workload driving the increase
- Resources involved
- Cost impact
After, it surfaces three recommended next steps. The answer that would have taken an engineer several hours to piece together manually is ready to share with finance in a single conversation.
Step 5: Cost becomes part of how the team operates
With spend visible at the team level through Coststreams, EC2 costs are no longer something that surfaces once a month in a bill nobody can fully explain. Engineers can see what the services they own cost to run. Finance can see spend by Business Unit without waiting on a report. The investigation that started with a high bill becomes the foundation for a practice that keeps it under control.
Start optimizing EC2 costs with full visibility
AWS provides native tools for EC2 cost management, and they are genuinely useful:
- Cost Explorer shows historical spend
- Compute Optimizer surfaces rightsizing recommendations
- Trusted Advisor flags idle resources
The gap is that all three are retrospective: they tell you what happened, not what is happening now, and they do not route a finding to the person who can fix it.
EC2 cost is a layered problem, and the teams that manage it well treat optimization the same way they treat performance monitoring: something running continuously in the background, not something that gets a calendar invite once a quarter. The good news is that maintaining that discipline has increasingly become a tooling problem rather than a personal one.
North identifies EC2 optimization opportunities continuously, from commitment coverage gaps to oversized instances to spend anomalies, so teams are not discovering waste in the monthly bill.
Book a demo to see what your EC2 environment looks like with that visibility in place from day one.
This blog was originally published in 2025 and has been updated in 2026 to reflect a deeper look at EC2 cost drivers, including expanded coverage of commitment strategy, instance sizing, and data transfer costs, as well as a step-by-step walkthrough of how teams use North to address each layer.

Related article
.png)
Book a demo
Get started in as little as 5 minutes with no long-term contracts or lock-ins. Pay month-to-month and stay flexible.


Make your cloud work smarter today
Get started in as little as 5 minutes with no long-term contracts or lock-ins. Pay month-to-month and stay flexible.


