Cloud tagging done right: A guide for modern teams
Good cloud tagging turns your cloud bill from a monthly mystery into a clear picture of how your business runs. This guide walks through what it is, the best practices for implementing it well, and the cost attribution approaches teams are adopting when manual tagging hits its limits.

Good cloud tagging turns your cloud bill from a monthly mystery into a map of how your business actually runs. Finance can allocate costs accurately, engineering can identify optimization opportunities, and leadership can make informed decisions backed by real data.
That’s the goal. In practice, though, most teams encounter some common challenges along the way:
- Tags often get applied inconsistently across teams, especially as organizations scale
- Resources sometimes get provisioned without any tags at all
- Naming conventions tend to drift, creating overlapping labels that take effort to reconcile
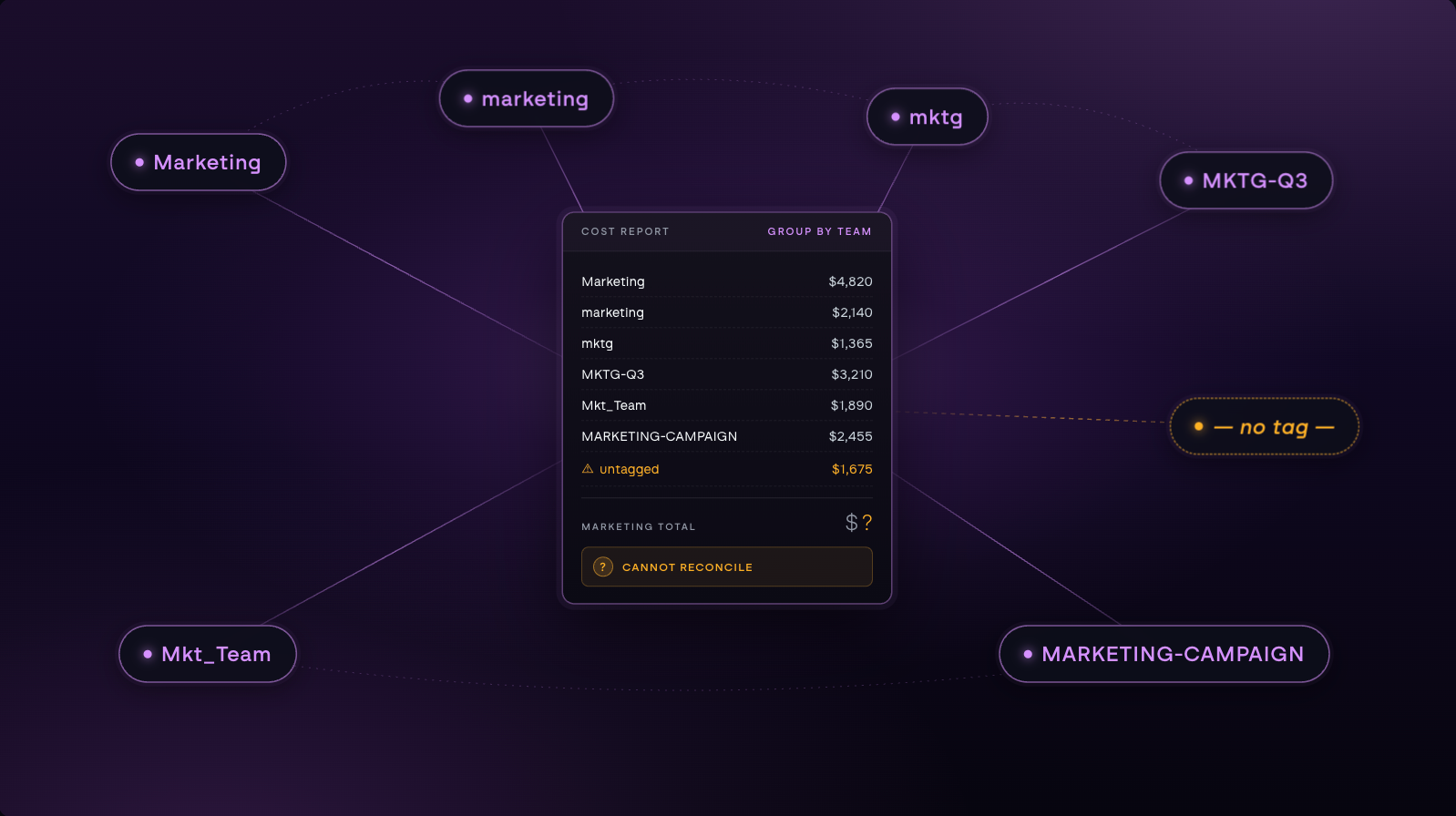
This guide walks through what cloud tagging is and the best practices for implementing it effectively. It also looks at why many teams are exploring AI-powered cost allocation as an alternative or complementary approach to solving the underlying visibility problem tagging was designed to address.
What is cloud tagging?
Imagine a credit card shared by everyone in a household. At the end of the month, the statement shows some categories: groceries, gas, streaming. But within each category, the details stop there. The grocery line is $400, but you can't tell whether that's because someone bought 20 pounds of tomatoes for a backyard event or because someone splurged on champagne. The category alone isn't enough to act on.
A cloud bill works much the same way. By default, you can see how much you spent on compute, storage, or networking, but the detail underneath is opaque. Was the compute spike driven by a long-running training job? A misconfigured staging environment? A specific team's workload? Without more context, the categories on the bill don't tell you why the numbers look the way they do.
Cloud tagging brings clarity to that view. Tags are key-value metadata labels you attach to cloud resources (compute instances, storage buckets, databases, managed services) so you can group, filter, and attribute costs along dimensions that reflect how your business operates.

With these labels in place, you can answer questions that a raw bill can’t:
- How much is the platform team spending this quarter?
- What does
Project North-v2cost to run in production versus staging? - Which cost center should be charged for this database?
Cloud providers like Amazon Web Services (AWS), Google Cloud Provider (GCP), and Microsoft Azure do include some metadata out of the box, such as region, service type, and operation type. That’s useful for engineering analysis, but it describes the infrastructure itself, not your organization.
Tags are how you add the business context: which team owns the resource, which product it supports, which cost center is accountable for it.
How AWS, Azure, and GCP handle tagging differently
All three major cloud providers support tagging, but they each approach it slightly differently. Understanding these differences is helpful whether you’re working in a single cloud or operating across several.

AWS uses the term tags for its key-value pairs and offers a mature set of governance tools, including Tag Policies through AWS Organizations and Cost Allocation Tags. One thing worth knowing: Cost Allocation Tags need to be explicitly activated before they show up in Cost Explorer, which often surprises teams reviewing past spend. AWS supports up to 50 tags per resource.
Microsoft Azure uses the same key-value model and integrates tagging deeply into Azure Policy, which makes it straightforward to enforce tagging requirements at the moment a resource is provisioned. Azure also supports up to 50 tags per resource, and tag data flows natively into Cost Management for reporting.
GCP takes a different approach by separating the concept into two: labels (up to 64 per resource) are used for cost allocation and reporting, while tags are a newer construct designed for network and IAM policy decisions. This distinction is worth knowing if your team is moving from AWS or Azure, where "tag" covers both use cases. It's also useful to be aware that GCP labels don't appear in billing data instantly. There's a short processing lag, and support varies somewhat by service.
In a multi-cloud environment, tagging isn’t one practice but three related ones. Each provider has its own schema, governance tools, and billing pipeline, and a tagging strategy that works well in one cloud may need to be adapted for the others.
Why cloud tagging matters, and why it's harder than it looks
Without tagging, your cloud bill is a black box. Finance, engineering, and leadership all see the same number, and nobody can tell who owns what, what caused a spike, or whether a specific product line is trending the wrong direction.
Done well, tagging unlocks four capabilities that shape how an organization understands and manages its cloud spend.
Cost allocation
Cost allocation is the practice of mapping cloud spend back to the teams, products or business units responsible for it.
On its own, a $400,000 monthly compute bill is just a number. With tags, it becomes something more actionable:
- $180,000 to the platform team
- $90,000 to the data team
- $130,000 to the customer-facing product team

Chargeback and showback
This breakdown is what makes chargeback and showback models possible:
- Chargeback: The platform team’s $180,000 actually shows up as a charge against their budget
- Showback: The team sees the number but isn’t formally billed for it
Both approaches create accountability, but chargeback tends to drive faster behavior change because there’s a real budget consequence.
If we go back to the $400,000 compute bill example, with environment tags in place, a team can see that their staging environment alone is costing $12,000 a month. That visibility makes inefficiencies (like test instances running overnight) easy to spot and fix. Without tags, that cost stays hidden in the broader total.
Resource governance
Resource governance is about knowing what exists in your cloud environment, who owns it, and whether it still needs to be there.

This sounds straightforward, but it’s one of the most common places cloud spend quietly grows. Here’s a pattern that plays out at almost every growing organization:
- An engineer spins up a database for a short-term experiment
- The experiment ends, but the database keeps running
- The engineer moves to a different team
- A year later, no one remembers the database exists
The database keeps accruing storage and backup costs in your environment, even though no one is using it. These are sometimes called orphaned or ghost resources, and they can quietly add up to a meaningful percentage of total spend.
Tags help prevent this. When every resource carries an “owner” tag and a “project” tag, you can:
- Run regular audits to flag resources whose owner has left the team
- Identify resources tied to projects that have wrapped up
- Automate cleanup policies (e.g. “any resource tagged ‘
Environment:dev’ that hasn’t been accessed in 30 days gets flagged for review”)

Otherwise, this kind of governance requires manual archaeology. This means checking creation dates, tracing IAM roles, asking around in Slack to see if anyone remembers who built what. With consistent tags, it becomes a routine report.
Security policy and compliance
Tags can carry classifications that drive access controls, compliance rules, and network policies. For example:
- A resource tagged
DataClassification: PII(personally identifiable information) might be restricted to specific IAM (identity and access management) roles, encrypted with a designated key, and excluded from certain network paths - A resource tagged
Compliance: HIPAAmight be subject to additional logging and retention requirements
This matters because security policy in the cloud is most effective when it’s automated and applied consistently. Manually checking every new resource against a checklist doesn’t scale. Tag-based policies do. They apply the moment a resource is provisioned and remain in effect for as long as the tag does.
A practical example: a fintech company might enforce a rule that any resource tagged Environment: production and DataClassification: customer-financial must live in a specific VPC (virtual private cloud), use approved encryption keys, and be excluded from public network access. The policy engine handles the enforcement and tags tell it which resources are in scope.
Operational visibility
When something breaks or a cost spike appears, tags are how you trace the issue back to something actionable. Compare two versions of the same alert:
- Without tags: “EC2 spend is up 40% this week”
- With tags: "EC2 spend in
Team: data,Project: ml-trainingis up 40% this week"
The second version tells you exactly where to look and who to talk to. This is sometimes called blast radius analysis: understanding the scope of a problem and which parts of the organization are affected.
For instance, if a misconfigured deployment accidentally provisions a database in an expensive region, an engineer with access to tagged cost data can identify the offending project, team, and owner within minutes. Without that context, the same investigation might involve digging through deployment logs, checking with multiple teams, and piecing together a timeline from scratch.
The pattern is the same across all four of these capabilities: tags turn ambiguous data into something a person can actually act on.
Cloud tagging best practices, if you're doing it manually
If you're building or fixing a tagging practice, here's what works.
1. Define your taxonomy before you touch a resource

The most resilient tagging systems start with a deliberate taxonomy rather than evolving reactively. When tags get added ad hoc as needs arise, teams often end up with overlapping labels and inconsistent meanings that take significant effort to reconcile later.
To avoid this, start with a required minimum tag set. A reasonable baseline:
- Owner: the team or individual responsible for the resource
- Environment: production, staging, development, test
- CostCenter: maps to your finance chart of accounts
- Project: the initiative or product this resource supports
- Application: the specific service or app within a project
Involve finance, engineering, and operations in this decision. A taxonomy that works for all three is far more useful than one shaped by a single team's needs.
2. Standardize naming conventions and document them
Pick a casing convention (lowercase with hyphens, capitalized words run together, etc.) and enforce it everywhere. The specific choice matters less than the consistency. north-cloud, NorthCloud, and northcloud are three different tags that won't aggregate correctly.

Avoid abbreviations that only one team understands. mktg-q3-prj makes sense to whoever created it, but anyone else looking at a cost report has to guess. A tag convention nobody can find is a convention that’s hard to follow.
Write the schema down somewhere discoverable, such as pinned in a Slack channel or a GitHub README page. This way, any newly hired engineer will have a stylebook to follow rather than guessing.
3. Enforce tags at provisioning (not after)
Enforcement is most effective when it happens at provisioning time. Making untagged resources impossible to deploy is what keeps tagging consistent as the organization grows.
There are two complementary layers that work well together:
- Infrastructure-as-code: the practice of defining cloud resources in configuration files rather than through a console. Tools like Terraform, Pulumi, and AWS CloudFormation read those files and provision resources accordingly. Because the configuration is just code, you can require that every resource definition include certain tags before it will deploy. If an engineer writes a Terraform file for a new database without an
Ownertag, the deployment fails before anything is created. - Cloud-native policy enforcement: built-in-policy tools from each cloud provider that act as guardrails on top of whatever provisioning method is being used. These policies sit at the platform level and block actions that don’t meet defined conditions, including the creation of resources that are missing required tags. They work even if someone bypasses infrastructure-as-code and tries to provision something through the console or CLI directly.
The major providers each offer their own version:
- AWS: Tag Policies via AWS Organizations, combined Service Control Policies
- Azure: Azure Policy with deny effects at subscription or management group level
- GCP: Organization Policies with custom constraints on label requirements
"Tag or it won't deploy" sounds strict, but it’s one of the few approaches that holds up at scale. By the time a missing tag shows up in a report, the resource is often already part of weeks of accumulated cost data that’s hard to reconstruct.
4. Audit and remediate on a schedule
Tag drift is inevitable without active maintenance. Setting up a regular review cycle helps prevent drift from accumulating:
- Schedule monthly tag coverage reports to flag untagged and mistagged resources before they accumulate
- Assign specific ownership for remediation, since work without a clear owner often slips through the cracks
- Aim for 95%+ coverage on required tags as your baseline. Below that, reports start to show meaningful gaps. Above it, you’re usually catching exceptions rather than systemic issues.
5. Tag for business outcomes, not just for accounting
A tagging taxonomy built around the finance org chart (departments and cost centers) will close the books neatly. It often falls short, though, when teams ask product-level questions:
- How much does this feature cost to run?
- What’s our infrastructure cost per customer?
- Which product line has the best unit economics?
- Is this customer segment more expensive to serve than others?
Adding tags that map to products, features, or customer segments alongside the standard accounting tags makes those questions answerable. A few examples of what this looks like in practice:
Product: checkoutalongsideCostCenter: engineeringFeature: ml-recommendationsalongsideTeam: dataCustomerTier: enterprisealongsideEnvironment: production
These outcome-oriented tags often surface insights that pure cost center reporting can’t. For example, a single feature might be quietly consuming more resources than the team responsible for it realizes, or a particular customer segment might be running at a much thinner margin than the high-level numbers suggest.
Most mature organizations use both kinds of tags together: standard accounting tags as a baseline for everyone, with outcome-oriented tags layered on top for the resources where product-level visibility matters most.
The takeaway: the standard accounting tags (Owner, Environment, CostCenter, Project, Application) tell you who spent what. Outcome-oriented tags tell you what that spending is producing.
A different approach: cost attribution without tagging
Tagging is still the most common foundation for cloud cost attribution, but it's not the only one. A growing number of teams are using cloud cost management platforms that attribute cloud spend without depending on tag coverage being complete or consistent.
The approach is worth understanding whether you're actively considering this approach, evaluating whether your current tagging practice is enough, or just trying to make sense of where the space is heading.
How it works
The core idea is that cloud providers already expose a lot of metadata about every resource, including region, service type, operation type, and account. Tags add more metadata on top when they're applied, but they're one input among many, not the foundation.
North is a cloud cost management platform built specifically to turn that metadata into actionable cost attribution. It can:
- Pull billing data from all your cloud providers automatically
- Normalize that data into a single, queryable view
- Let you group spend by any available dimension, including account, region, service, project, environment, team, or tag if it exists
- Drill down to the individual resource or job level, not just the aggregate billing line
Within North, the Coststreams feature ingests cost data across all your cloud providers and lets teams define top-level groupings (called business units) that allocate spend based on whatever combination of attributes makes sense.
Each business unit can have its own budget, its own owners, and its own dashboard view. Tags become one dimension among many, not the foundation the system depends on.
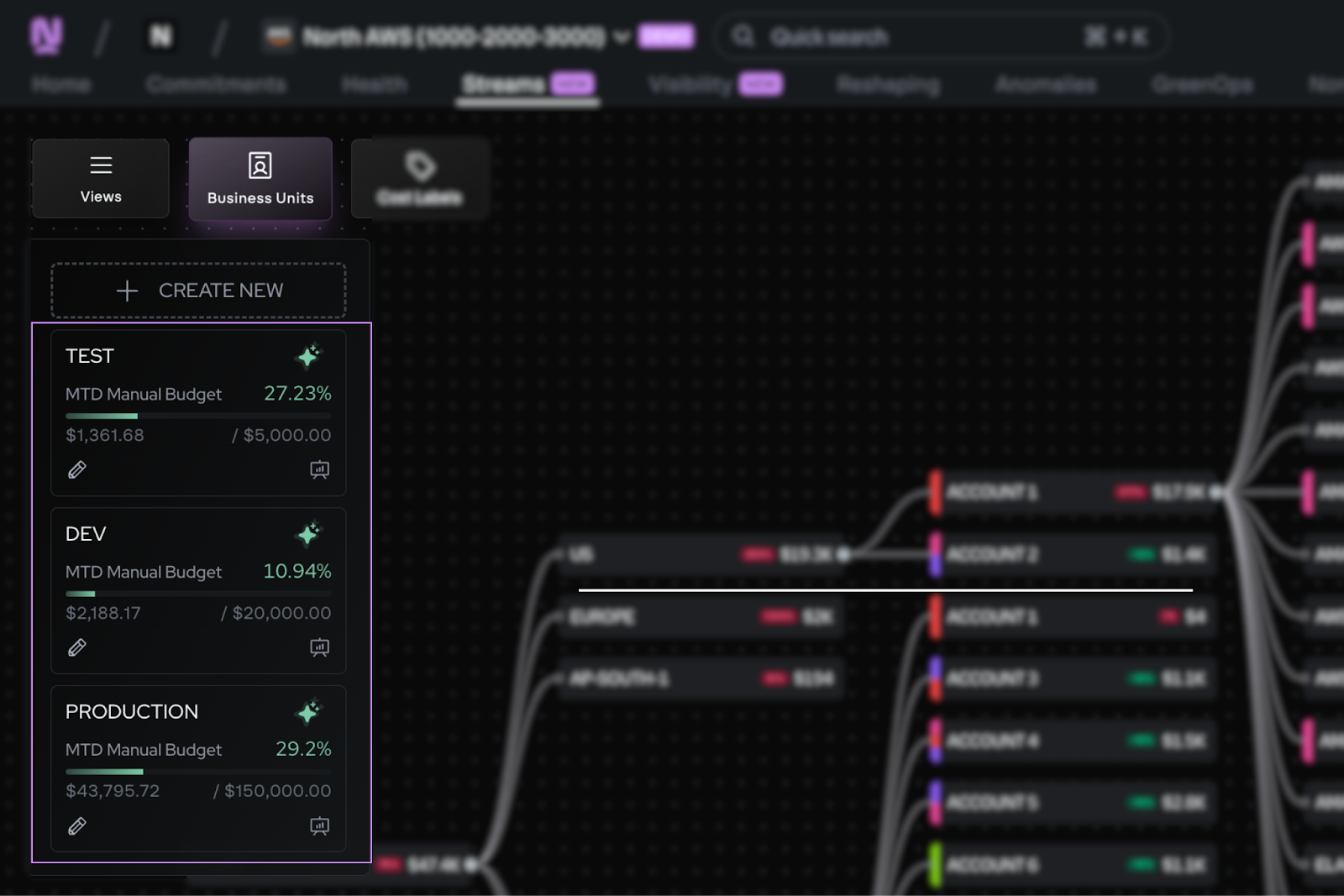
Coststreams Business Units panel showing month-to-date budget tracking for Test, Dev, and Production environments alongside the Cost Flow diagram.
Coststreams also includes lighter-weight features for analytical work, like CostLabels for visual grouping across business units and Cost Units for connecting cloud spend to business metrics such as cost per customer or cost per click.
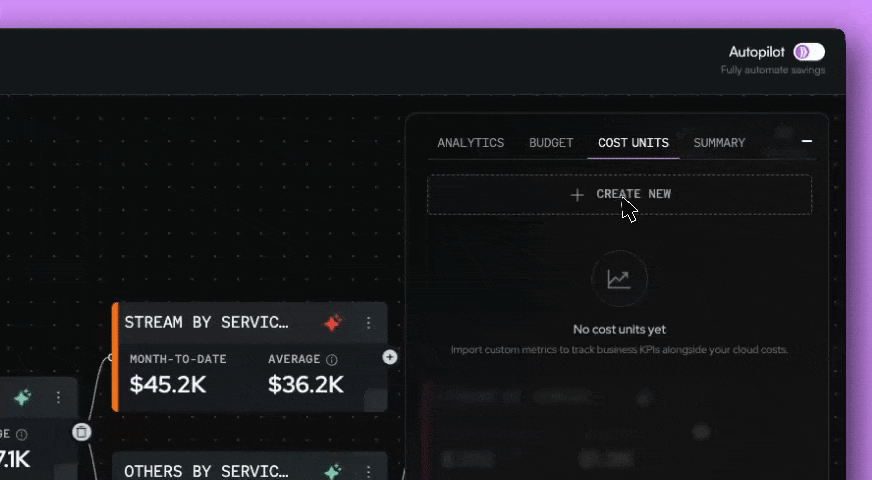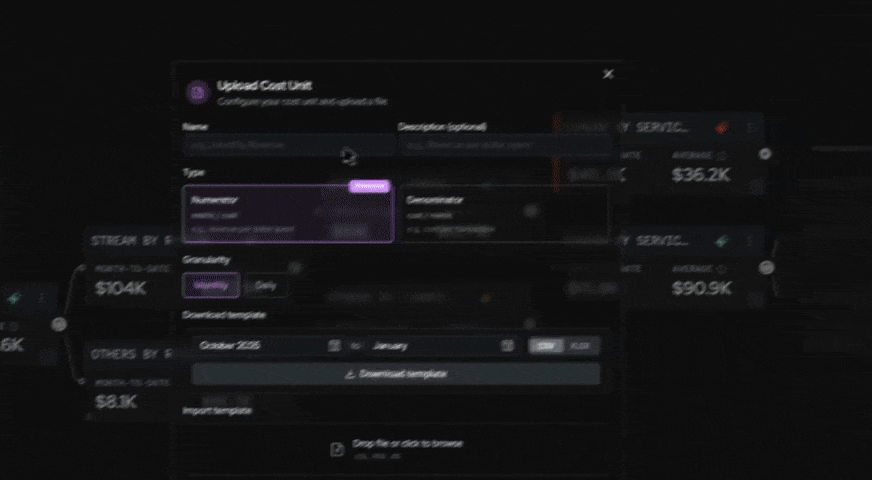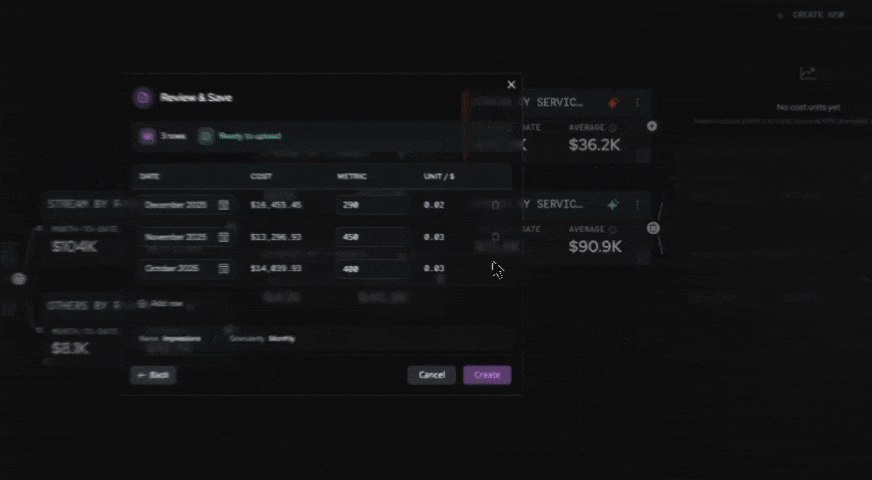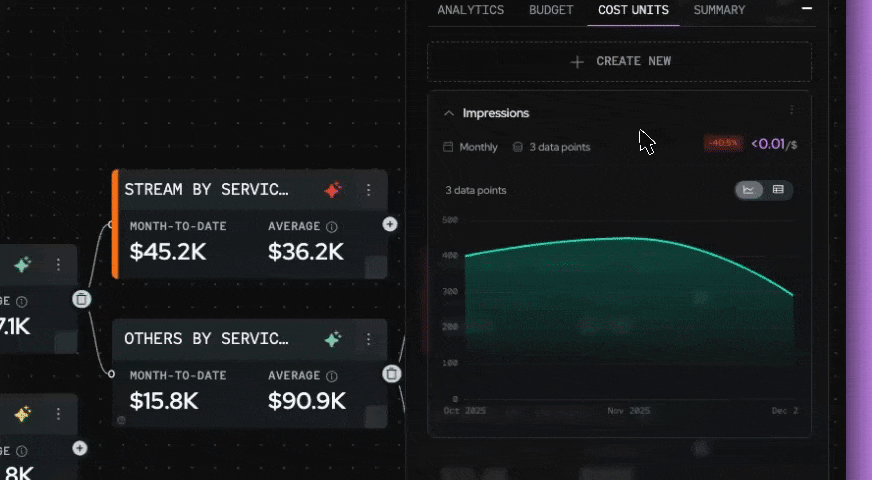
Two related features round out the picture: Anomaly Detection, which surfaces unusual cost activity across your environment, and Noros, North’s FinOps AI copilot. Together, these tools form the workflow that handles the kind of investigation tagging alone would struggle with.
A practical example: Tracking down a cost spike
Let's say your team has been seeing unusual cost activity in a development environment. The total month-to-date spend is sitting close to production, which shouldn't happen. Production is where customer-facing workloads run at full throttle. Development environments are just where engineers build and iterate, so they should cost a small fraction of production.
Some of the dev environment cost might be expected. AI training workloads often run in dev environments, and a team might know they're spending several thousand dollars a month on training to improve a model. But beyond that, one specific service stands out: an unusually large cost in something like Glue or another managed data integration service.

To investigate, you open the North app and navigate to Coststreams. Here's how it plays out.
Step 1: Flag the anomaly
In the Coststreams dashboard, you can see dev environment costs sitting alongside production and test, broken down by service. When the dev numbers start tracking close to production, that's the signal something's worth investigating.
To pinpoint exactly when and where the anomaly started, you switch over to Anomaly Detection. This view surfaces every cost spike across your environment with timestamps, severity ratings, and the affected service. From here, you can see that the largest spike (a $401.72 jump representing a 1,324% deviation) happened on April 9, 2026, on a Glue ETL job tied to the AI/ML cohort. That's the thread to pull on.
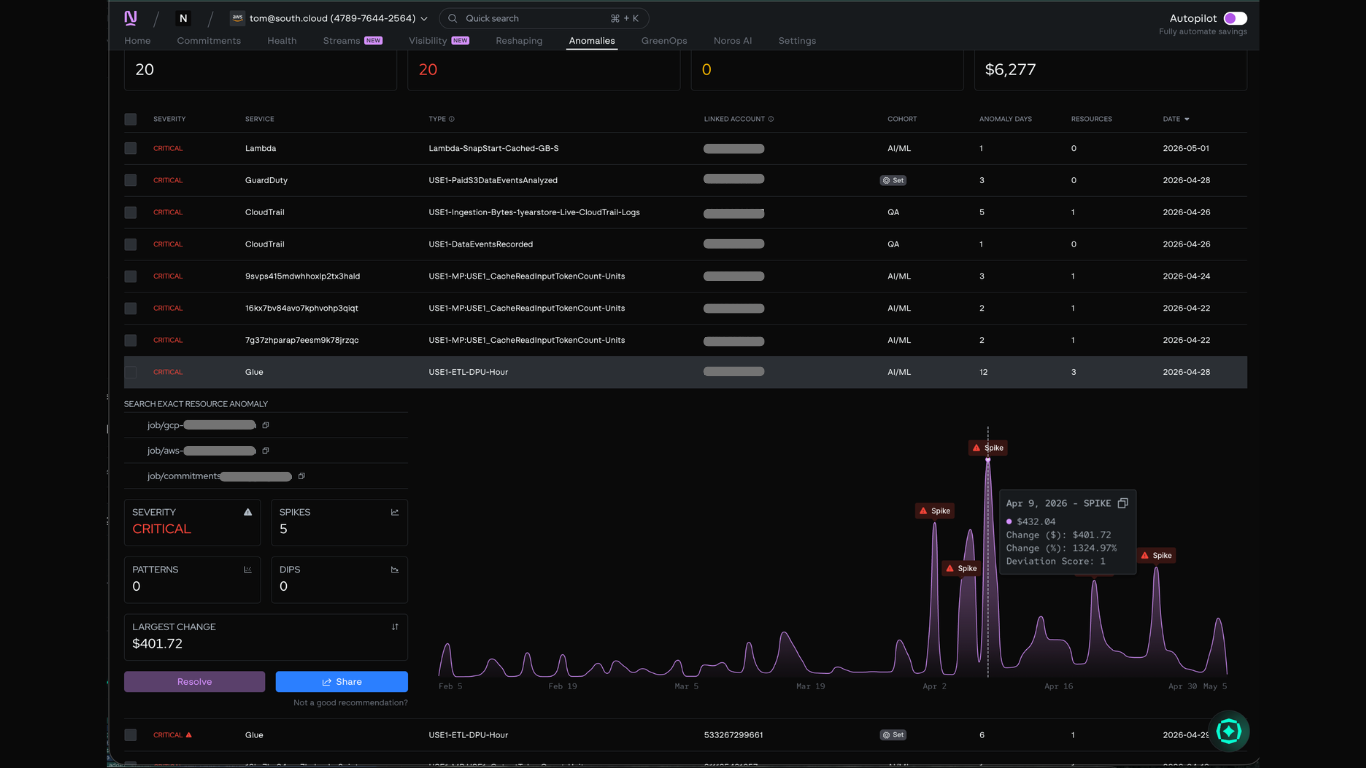
Step 2: Drill down to the resource
Inside Anomaly Detection, you can click into the specific anomaly to see the full pattern at the resource level. The panel reveals the exact job driving the cost, the severity rating, the number of spikes detected over time, and the largest single change.
This is the level of detail tag-based attribution typically can't reach. Not just "this service is expensive this month," but the specific job, the specific time window when the cost started climbing, and a visualization of how the pattern has played out over weeks or months. From here, you can see whether the spike is a one-time anomaly, a recurring pattern, or part of a larger trend that needs deeper investigation.

Step 3: Ask Noros to explain the spike
Once you've identified the specific anomaly, the next step is understanding why it happened. Open Noros and paste in the resource identifier. A simple prompt is enough: "Can you tell me why this anomaly happened and how to resolve it?"

Noros pulls in the relevant anomaly data, analyzes the cost pattern, and surfaces what's driving the spike. In this case, the assistant identifies that the Glue job is part of a broader pattern (related anomalies across other resources, with their own cost impacts and severity ratings) and lays out the context needed to diagnose the underlying cause.
Step 4: Get a resolution plan you can act on
Noros’ response lays out the most likely root causes ranked by probability (a sudden data volume surge, a misconfigured DPU allocation, a backfill or reprocessing run, or inefficient job logic), along with immediate actions to take and longer-term optimization steps.
.jpeg)
The immediate actions are practical and specific:
- Review job metrics for the affected date
- Verify the input data size
- Check whether the job configuration is over-provisioned
The optimization steps go further, suggesting things like enabling job bookmarking to avoid reprocessing, partitioning data to limit scan scope, or switching to a more cost-efficient runtime configuration.
What would otherwise take an engineer hours to piece together (tracing relationships between resources, reviewing historical cost patterns, and figuring out what to actually do about it) is condensed into a single conversation, ready to send directly to the developer or team responsible.
What made this possible
The investigation inside Coststreams takes roughly two minutes from spotting the anomaly to having a resolution plan. Without it, the same analysis might take an engineer somewhere between two and four hours, and that's assuming they already have access to all the underlying data. For someone less involved in the architecture, like an executive, surfacing the issue at all might not be possible without significant help.
This is what cost attribution looks like when it's grounded in resource-level metadata rather than tag coverage. The development environment didn't need a comprehensive tagging policy. The combination of provider-level metadata, account structure, and resource naming was enough to reach the right answer in minutes.
Where this approach fits
This kind of tooling is most valuable for teams in specific situations:
- Fast-scaling engineering organizations that don't have the bandwidth to build and maintain a tagging discipline from scratch
- Companies with significant legacy infrastructure where retroactive tag remediation would take years
- Multi-cloud environments where the overhead of maintaining three separate tagging systems is genuinely difficult to justify
- Teams that have invested in tagging and found that the organizational discipline required to sustain it is closer to a full-time job than a background process
It's worth being clear about what this approach isn't. It doesn't make tagging useless. Tags remain a valid dimension to split by, and teams with strong tagging practices can use them alongside other attributes.
What changes is that tagging is no longer load-bearing. Cost attribution becomes meaningful before tag coverage is complete, and stays meaningful even when tag coverage drifts.
Get started with cloud tagging today
Cloud tagging is foundational to understanding where your cloud spend goes and why. Done well, it gives finance, engineering, and leadership a shared view of how the business actually runs.
Ready to bring that clarity to your own cloud bill? Start with the basics: define a minimum tag set, agree on a naming convention, and enforce it at provisioning. From there, regular audits and outcome-oriented tags will sharpen the picture over time.
And when tagging alone hits its limits, North's Coststreams can attribute spend across your cloud providers without depending on perfect coverage.
Book a demo to see what your cost data looks like with resource-level visibility from day one.

Related article
.png)
Book a demo
Get started in as little as 5 minutes with no long-term contracts or lock-ins. Pay month-to-month and stay flexible.


Make your cloud work smarter today
Get started in as little as 5 minutes with no long-term contracts or lock-ins. Pay month-to-month and stay flexible.


